はじめに
こんにちは、バックエンドエンジニアの田中 湧大 (@Romira915)です。
近頃、PR TIMESのバックエンド基盤においてAmazon RDS for PostgreSQLのCPU使用率が継続的に上昇していることが観測されるようになりました。
以前は20%前後→現在は40%前後に上昇しており、ピークタイムには90%を超えてアラートが発報される状況も発生しています。
このまま放置した場合、以下のようなリスクが顕在化する恐れがあります。
- API レスポンスの悪化によるユーザー体験の低下
- 重要なデータ操作失敗によるサービス全体へのクリティカルな影響
そこで、バックエンドエンジニア数名で 一時的な改善チーム を立ち上げ、原因調査および改善に着手しました。
本記事では、その調査内容と改善対応についてまとめます。
調査方針
まず、CPU 使用率の上昇を 時間軸の観点 で切り分けました。
- 長期的にじわじわ上昇している問題
- 短期的にスパイクする問題
性質が異なるため、切り分けて調査を進めました。
長期的に CPU 使用率が上昇している問題
Mackerel のメトリクスを確認したところ、2024 年 7 月頃から 2025 年 11 月にかけて CPU 使用率が徐々に上昇していることが分かりました。
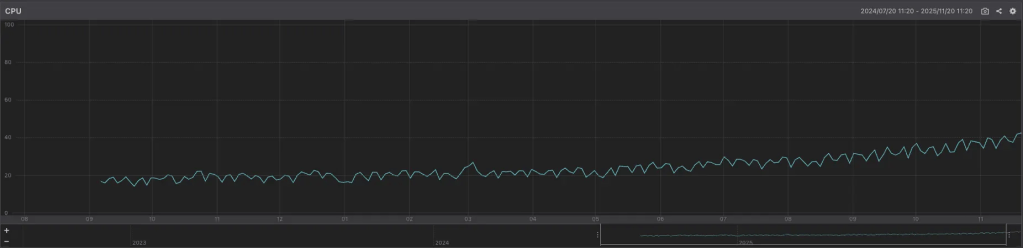
- 以前は 20% 前後 で推移していた平均 CPU 使用率が
- 現在は 40% 前後 まで上昇
明確なスパイクではなく、負荷が蓄積され続けている状態 であることが読み取れます。
短期的に CPU 使用率が上昇する問題
一方で、時間帯によっては CPU 使用率が急激に跳ね上がるタイミングも確認できました。
- 毎時 15 分・45 分 に CPU 使用率がスパイク
- このタイミングは RSS 更新用バッチ が起動する時間帯
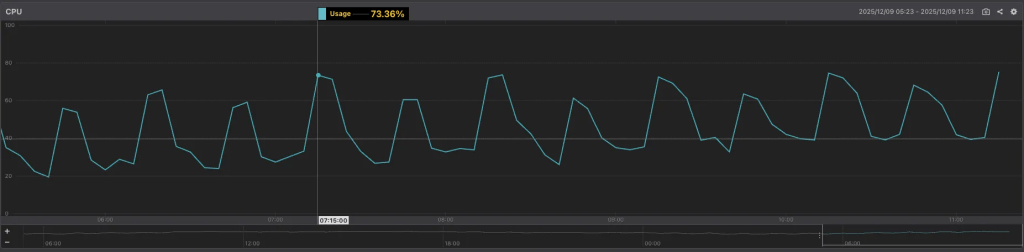

毎時 15 分・45 分に CPU 使用率が跳ね上がる現象については、以前から RSS 更新処理の実行タイミングと一致していること、また当該処理が一定の負荷を伴うことは認識されていました。 ただし、当時は RDS の CPU 使用率に十分な余裕があったため、影響度は限定的と捉え、対応の優先度を下げたまま運用していました。
その後、CPU 使用率のベースライン自体が上昇してきたことで、従来から認識していた RSS 更新処理の負荷が無視できなくなり、今回あらためて対応対象として扱うことにしました。
Database Insights を用いたクエリ分析
本章以降に登場する実行計画やパラメータ(EXPLAIN ANALYZE、work_mem 等)は PostgreSQL を前提に記載しています。
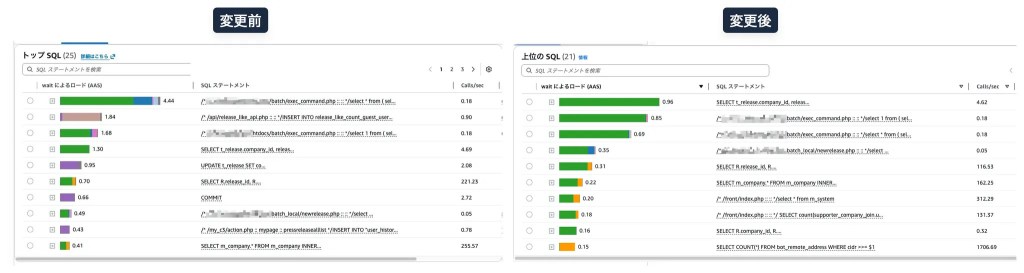
次に、Amazon RDS の Database Insights(旧 Performance Insights) を利用し、CPU を消費している具体的なクエリを調査しました。
Database Insights の Top SQL を確認し、今回の目的が CPU 使用率の低下であることから、待機イベントのうち CPU WAIT(緑) に着目して分析を進めました。


その結果、CPU WAIT が高いクエリを洗い出し、チーム内で分担しながら個別に詳細調査を進めました。
調査①:プレスリリース閲覧時に実行されるクエリ
クエリの概要
最初に注目したのは、以下のようなクエリです。
- Calls/sec が約 221
- プレスリリース詳細ページにアクセスした際に発行される

SELECT
R.release_id,
R.release_comple_date,
R.reference_url,
R.media_secret_flg,
C.company_id,
C.company_name,
T.release_type_id,
-- 一部省略
EXISTS (
SELECT *
FROM t_release_embedded remb
INNER JOIN theta360_contents tc ON tc.id = remb.content_id
WHERE remb.company_id = :company_id
AND remb.release_id = :release_id
) AS exists_360_contents,
R.agif_image_file_name1
FROM
t_release R
INNER JOIN m_company C ON R.company_id = C.company_id
INNER JOIN m_release_type T ON T.release_type_id = R.release_type_id
WHERE
R.company_id = :company_id
AND R.release_id = :release_id
AND C.del_flg = FALSE
AND R.del_flg = FALSE
AND R.stop_flg = FALSE
AND R.comple_flg = TRUE;実行計画の確認
EXPLAIN ANALYZE を実行したところ、
- 実行時間は 0.149ms
- 主要テーブルは PK による Index Scan
- Seq Scan が発生しているテーブルも 100 行程度の小規模マスタ
- 見積行数と実行結果の乖離もほぼなし
以上から、クエリ単体の性能には問題がない と判断しました。
Calls/sec が多い原因の特定
Calls/sec の多さから N+1 問題 を疑い、コードレベルでも調査しましたが、
- 1 API Call = 1 Query の実装
- 不要なループや重複発行はなし
アクセスログを分析した結果、Database Insights の Calls/sec (1 秒あたりのクエリ実行回数) と 1秒間の平均リクエスト数 がほぼ一致しており、アクセス数の増加が CPU 使用率に影響していることが分かりました。
| 1秒間の平均リクエスト数 |
|---|
| 221.13 |
対応策
過去のブログでも触れられている通り、プレスリリース詳細ページのキャッシュは、更新・削除時にキャッシュをパージする仕組みが当初存在しなかったため、TTL を 60 秒に設定していました。
TTL を長くすると、更新や削除が即座に反映されないリスクがあったためです。

現在は、プレスリリースの更新・削除イベントを SQS に送信し、それをトリガーに対象ページのキャッシュをパージする Lambda が実行される仕組みが整備されています。これにより、更新反映の即時性を担保したまま、キャッシュの TTL を延長できる状態になりました。
この前提を踏まえ、今回の対応では以下を実施しました:
- プレスリリース詳細ページのキャッシュ TTL を30分に延長
- キャッシュヒット率を高め、DB へのクエリ発行を削減
この方針により、高頻度アクセス時のキャッシュ活用を最大化しつつ、データ更新があるケースでも最新状態が保たれる仕組みとなっています。
対応後の改善結果
キャッシュ TTL 延長を反映した後、Amazon RDS の Database Insights および各種モニタリング指標を用いて、対応前後の変化を確認しました。
主な指標の変化
| 指標 | 対応前 | 対応後 |
|---|---|---|
| Database Insights Calls/sec | 221.13 | 117.11 |
| ECS 平均 CPU 使用率 | 約 35% | 約 15% |
| Cache Hit Rate | 約 30% | 約 60% |
Database Insights 上で確認していた Calls/sec は約半分まで低下しており、プレスリリース詳細ページへのアクセスの多くがキャッシュ経由で処理されるようになったことが分かります。
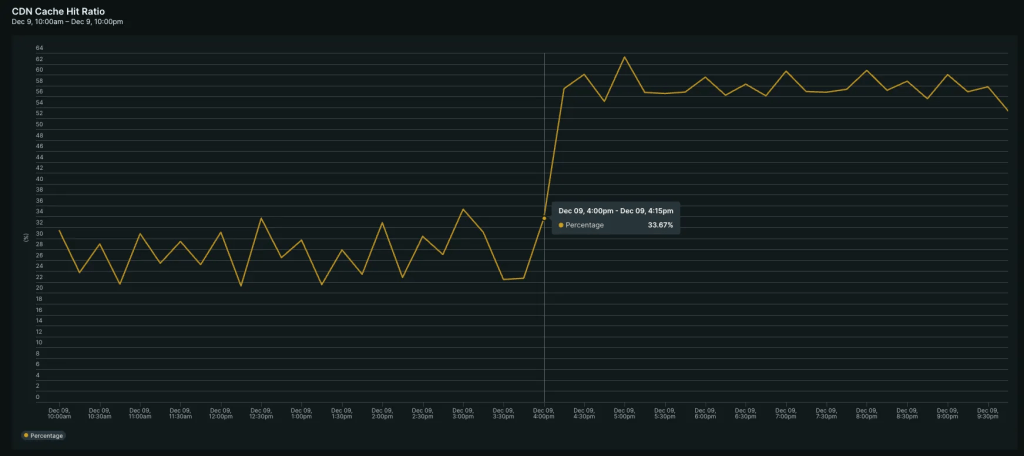
これに伴い、プレスリリース詳細ページが稼働している ECS の平均 CPU 使用率も大きく低下しており、DB へのリクエスト数削減がインスタンス全体の負荷軽減につながったと考えられます。

また、CPU 使用率低下に伴い、ECS のタスク数も 平均 9〜10 程度から、最小値として設定している 7 で安定するようになりました。
今回の調査①では、クエリ単体の性能に問題がなくても、実行頻度が高いこと自体が CPU 使用率上昇の要因になり得ること、また キャッシュ TTL の見直しが有効な改善手段になり得ることが、指標の変化から確認できました。
調査②:一覧取得クエリにおける深刻な遅延
次に、より深刻な問題が見つかったのが プレスリリース一覧取得用のクエリ です。

SELECT t_release.company_id,
release_id,
release_comple_date,
media_secret_flg,
identifier,
-- 一部省略
(SELECT JSON_AGG(json_build_object('kijineta_tag', KT.kijineta_tag)) as kijineta_tag_data
FROM t_release_tag RT
INNER JOIN
m_kijineta_tag KT
ON
RT.kijineta_tag_id = KT.kijineta_tag_id
WHERE RT.release_id = t_release.release_id
AND RT.company_id = t_release.company_id
AND KT.del_flg = FALSE)
FROM t_release
INNER JOIN m_company ON t_release.company_id = m_company.company_id
WHERE comple_flg = TRUE
AND t_release.del_flg = FALSE
AND stop_flg = FALSE
AND ((release_comple_date = '2025-12-04 09:49:49' AND identifier < 5783632)
OR release_comple_date < '2025-12-04 09:49:49')
ORDER BY release_comple_date DESC NULLS LAST, identifier DESC
LIMIT 40実行計画の確認
EXPLAIN ANALYZE の結果、実行時間は 約 31 秒 に達しており、そのうち 約 9 割をサブクエリが占めている ことが分かりました。
SubPlan 1
-> Aggregate ... (actual time=705ms loops=40)- メインクエリで 40 件取得
- その 1 件ごとにサブクエリが実行
- 結果として 40 回ループ
インデックス自体は使用されているものの、
構造的に非常に非効率なクエリ となっていました。
対応策
- クエリを 2 回に分ける方針としました。
- 元のクエリでは、40 件取得する際に 40 回サブクエリが実行される構造になっており、一覧取得と付随データの取得を分離することで、この N+1 構造を解消します。
本クエリについては、今後対応を進めていく予定です。
調査③:バッチ処理から実行されている SQL の影響
Database Insights を確認していく中で、API リクエスト由来のクエリとは別に、バッチ処理から実行されている SQL も CPU WAIT の上位に現れていることが分かりました。
/* <app_root>/batch/exec_command.php :: :: */ select ...
/* <app_root>/batch_local/newrelease.php :: :: */ select ...
これらの SQL のうち、exec_command**.php から実行されているクエリが最も CPU WAIT を消費しており**、
Database Insights 上では 他の上位クエリと比較して 3〜4 倍程度の WAIT を占めている 状態でした。
これらの SQL は、プレスリリースに関する検索条件をもとに SQL を動的に組み立てて実行する SearchRelease() という関数から生成されています。
SearchRelease() は約 1,300 行にわたる実装で、長年にわたり機能追加を重ねてきた結果、プレスリリース一覧・検索・絞り込みなど複数の用途を一手に担う レガシーな処理 になっています。
SQL を確認したところ、ORDER BY がサブクエリの内側と外側の 2 箇所で指定されている構造になっていました。
SELECT *
FROM (
SELECT *
FROM (
SELECT ...
FROM t_release r
-- JOIN 等省略
ORDER BY
release_rss_date DESC,
r.release_comple_date DESC NULLS LAST,
r.release_date DESC,
r.release_id DESC
) x
) v
ORDER BY
v.release_rss_date DESC,
v.release_date DESC,
v.release_comple_date DESC,
v.release_id DESC
LIMIT 200;最終的な並び順と取得件数は外側の ORDER BY で決定されており、内側の ORDER BY は結果に影響せず、外側で上書きされるため不要と判断しました。
実行計画の確認
次に、実行計画を確認しました。
EXPLAIN ANALYZE の出力のうち、特に問題となっていたのは以下の部分です。
Sort Method: external merge Disk: 958000kB
Buffers: shared hit=18208149, temp read=736219 written=1102847
I/O Timings: temp read=1427.629 write=4306.443
Execution Time: 20535.813 msこの結果から、次の点が読み取れます。
- ORDER BY によるソート処理がメモリに収まらず、external merge(ディスクソート)になっている
- 約 1GB 近い一時ファイルがディスクに書き出されている
- ディスク I/O に多くの時間を消費しており、クエリ全体の実行時間が 20 秒超 となっている
対応策
上記の調査結果を踏まえ、以下の対応を行いました。
- SQL内の不要な内側 ORDER BY を削除
- 最終結果に影響しないソート処理を除去
- 該当クエリに対してのみ work_mem = 2GB を設定
- ソート処理をメモリ上で完結させ、external merge の発生を防止
対応後の改善結果
変更前後で EXPLAIN ANALYZE を比較した結果、
- 内側の ORDER BY 削除により、実行時間が約 2.5 秒短縮
- work_mem 設定を適用することで、external merge が解消
- ディスクへの一時オブジェクトの読み書きが発生しなくなった
- 結果として、実行時間は合計で約 6 秒以上短縮
されていることを確認しました。
対応後は、RSS 更新バッチ由来の SQL における CPU WAIT が大きく改善しており、対応前に同バッチの実行に伴って発生していた LWLock:WALWrite(茶色)や I/O: WALSync(紫)といった WAIT もほぼ見られなくなりました。 これらは RSS 更新バッチ実行時に、他の SQL にまで波及していた I/O 系の待機イベントであり、対応後はそうした影響も含めて解消されています。
さらに、RDS 全体のメトリクスを確認すると、今回の対応が DB 全体の負荷低減にも波及していることが分かります。
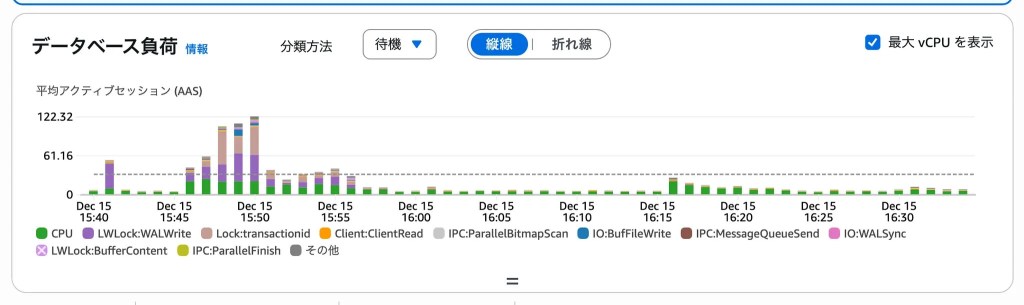
対応リリース前後のデータベース負荷
TotalIOPS を見ると、対応前に RSS 更新バッチの実行タイミングで周期的に発生していた高い I/O が抑制されており、ディスク I/O のピーク・ベースラインともに低下しています。

また、DBLoadCPU においても、対応前に見られていたRSS 更新バッチ実行時の CPU スパイクが緩和され、CPU 使用率に余力が戻っている状態が確認できました。

まとめ
本記事では、Amazon RDS の CPU 使用率上昇に対して実施した原因調査と改善対応についてまとめました。 調査の結果、CPU 使用率の上昇には、アクセス数増加による負荷の蓄積と、特定のクエリやバッチ処理に起因する局所的な高負荷が混在していることが分かりました。
調査①ではキャッシュ設定の見直しによりリクエスト数を削減し、調査③では RSS 更新バッチから実行される SQL の改善によって、CPU WAIT や I/O 系 WAIT、RDS 全体の負荷指標を改善することができました。
一方で、調査②で確認した一覧取得クエリについては、今後対応を進めていく予定です。







