
はじめに
こんにちは!PR TIMES第二開発部の加来安東です。
本記事では、AWS CloudTrail の監査ログを Google Cloud(BigQuery)上で分析できるように整備した事例についてご紹介します。
BigQuery Data Transfer Service(以下、DTS)による S3→BigQuery 転送と、スケジュールクエリによる整形処理をどのように組み合わせるかは、データ転送フローの設計上、重要なポイントとなります。
この記事は、次のような方に役立つ内容です。
- Athena 上で CloudTrail を扱っており、Google Cloud への移行を検討している方
- CloudTrail ログを BigQuery に集約しようとしているが、DTS とスケジュールクエリの使い分けに悩んでいる方
同じような構成を検討されている方の参考になれば幸いです。
この記事のゴール
- CloudTrail ログを S3 から BigQuery に取り込む構成を具体的にイメージできるようになる
- スケジュールクエリを安定運用する際の注意点を理解できる
AWS CloudTrailとは
AWSの操作履歴を記録する監査サービスです。どのAWSサービスで、誰が、いつ、何の操作をしたのかが分かります。
詳しくは、公式サイトをご覧ください。
背景・目的
これまで AWS 環境では Athena を利用して CloudTrail の監査ログを分析していました。しかし、他のサービスログやデータはすでにBigQueryに集約されており、分析基盤が分散していることで、管理やクエリ設計が複雑化していました。
そこで、ログやデータを BigQuery 上に統一し、分析基盤を一元化することによって運用効率と分析の柔軟性を高めたいと考えました。
加えて、BigQuery は大規模データ分析における基本性能が高く、クエリの実行速度やスケーラビリティの面でも優位であるため、CloudTrail ログの分析により適していると判断しました。
一方で、CloudTrail のログを DTS でそのまま BigQuery に転送しようとすると、スキーマ不一致が頻発し、安定的な運用が難しい課題も明らかになりました。
これらの背景を踏まえ、CloudTrail ログを BigQuery 上で安定的かつ柔軟に分析できる仕組みを構築することを今回の目的としました。
構成概要 (全体像)
全体構成は以下のようになっています。
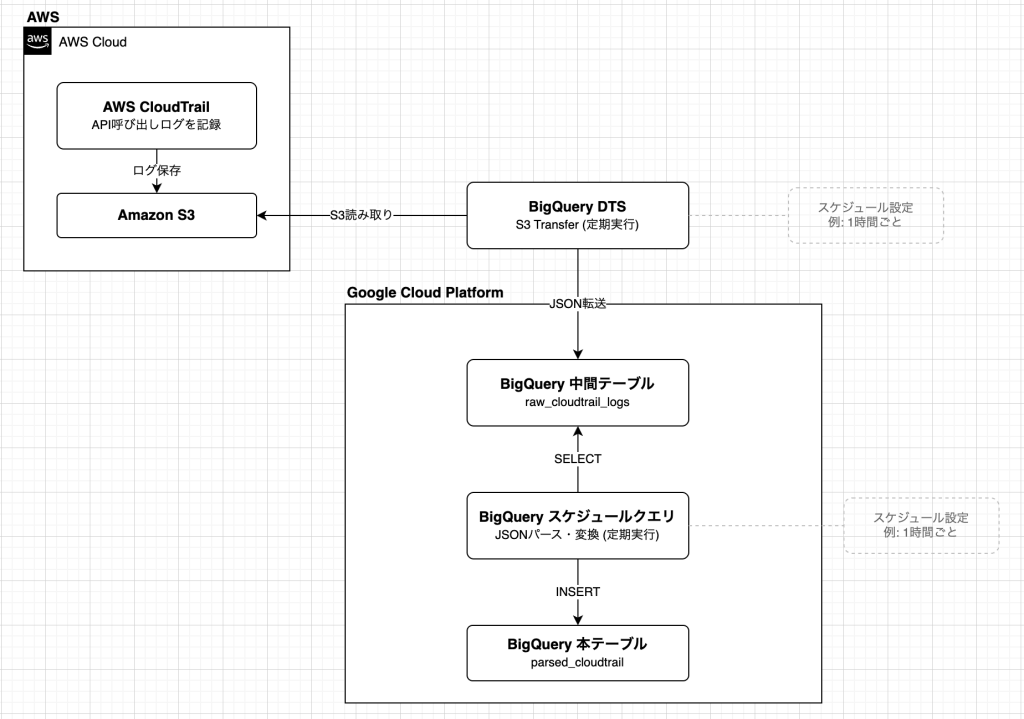
- AWS S3:CloudTrail ログを保存
- BigQuery DTS:S3 から中間テーブルへ転送する
- 中間テーブル:
Array<JSON>形式で生データを保持する - スケジュールクエリ:
- 中間テーブルからデータを整形して本テーブルに挿入
- 転送完了後に中間テーブルのデータを削除
この構成により、CloudTrail のスキーマ変更やネスト構造の差異にも柔軟に対応できるようにしました。
このあとは、それぞれの構成要素 (DTS・中間テーブル・スケジュールクエリなど) の設計判断について、解説していきます。
設計判断と実装のポイント
最初に考えたこと
最初に悩んだのは、CloudTrailのJSONログデータをどう扱うかでした。
当初は「DTS」を使えば、S3 上のログをそのまま BigQuery のテーブルに取り込めるだろうと考えていました。
しかし実際に試してみると、 CloudTrail の JSON は配列やネスト構造が非常に複雑で、イベントごとに JSON フィールド構成が異なることも多く、1回の転送で統一的に取り込むのはほぼ不可能でした。
ログの内容を欠損させず、かつ柔軟に受け取れるテーブル定義もなかなか思いつかず、いろいろと調べてみたものの有効な方法は見つかりませんでした。
そんなとき、先輩エンジニアの方から BigQuery の JSON 型を教えてもらい、突破口が見えてきました。
DTSから直接本テーブルに格納するのではなく、「JSON型を使い、どんな構造でも一旦受け止められる中間テーブル」を挟む構成に変更することにしました。
中間テーブルを入れた理由
CloudTrailログは以下のように、ネストされたRecords配列を持つ構造になっています。
{ "Records": [ { "eventVersion": "...", "eventName": "...", "awsRegion": "...", ... } ]}
配列やフィールド構造が固定でないため、最初から型を定義して取り込むことが難しい状況でした。
そのため、中間テーブルを ARRAY<JSON> 型として定義し、原文をそのまま保持するようにしました。
これにより、DTS転送時のスキーマ依存エラーを防ぎ、全てのログを確実に受け取れるようになりました。
本テーブル設計のポイント
本テーブルの設計では、主に次の2点を意識しました。
- パーティション設計
- ネスト構造の差異への対応
パーティション設計
スキャン効率とクエリのパフォーマンス、コスト最適化の観点から、BigQuery のテーブルにパーティションを設けました。
CloudTrailのデータはイベント発生時刻単位で蓄積・分析するケースが多いため、eventTime をパーティションキーとして採用しています。
この設計により、日時を条件にした絞り込みクエリのスキャン範囲を最小化でき、分析時のコスト削減とレスポンス改善の両立が可能になりました。
ネスト構造の差異への対応
CloudTrailのログでは、イベント内容によって JSON 構造が大きく異なる場合があります。
例としてここでは、requestParameters フィールドを出します。
下記のように内容が全く異なってきます。
{ "Records": [ { "eventVersion": "...", "eventTime": "...", "eventSource": "...", "eventName": "...", "requestParameters": { "logGroupName": "", "logStreamName": "" } }, { "eventVersion": "...", "eventTime": "...", "eventSource": "...", "eventName": "...", "requestParameters": { "agentName": "", "agentStatus": "", "agentVersion": "", "availabilityZone": "", "availabilityZoneId": "", "computerName": "", "iPAddress": "", "instanceId": "", "platformName": "", "platformType": "", "platformVersion": "", "sSMConnectionChannel": "" } } ]}
一見するとスキーマが安定しないように見えますが、調査の結果、ルート構造自体は共通しており、差異は一部のネスト要素に限られていることがわかりました。
そこで設計としては、ルート要素を明示的にカラムとして定義し、イベントごとに可変となる構造 (requestParametersなど)はJSON型で保持する方針を採用しました。
これにより、基本構造を固定しながら差分的な変更にも対応できるようにしています。
スケジュールクエリの想定外エラーとその対処
CloudTrail の取り込み処理では、複数の定期実行を自動化するために BigQuery の スケジュールクエリ を活用しました。
今回作成したのは、次の2種類です。
- 本テーブル挿入スケジュールクエリ:中間テーブルから本テーブルへデータを反映する処理
- 中間テーブル削除スケジュールクエリ:不要になった一時データを削除する処理
当初、これらを 1 つのスケジュールクエリに複数 SQL として登録していました。
しかし、運用開始後 1〜2 時間ほどで、以下のエラーが発生しました。
Error code 9 : Dataset specified in the query ('') is not consistent with Destination dataset 'cloudtrail_logs'.
BigQuery がクエリ実行時に destination dataset を空('')として認識してしまう状況であり、
クエリ内では明示的にデータセットを指定していたため、想定外の挙動でした。
原因の調査
調査の結果、スケジュールクエリはジョブ単位(= 1 SQL 文単位)で実行する構成がより安定するとわかりました。
このため、複数の SQL を1クエリにまとめて登録した場合、ジョブ内でのコンテキストが不安定になり、データセット参照が一部で失われる可能性があると考えられます (※推定)。
実際、私も以下の2つの処理を1つのスケジュールクエリにまとめて登録していました。
- 中間テーブルに入ったレコードを本テーブルへINSERTする
- 中間テーブルのレコードをTRUNCATEで削除する
対応と結果
上記の 2 処理を分離し、それぞれ独立したスケジュールクエリとして登録するよう変更しました。
この対応後は、destination dataset が空になるエラーは発生していません。
また、ジョブの実行単位が明確になったことで、ログ確認も容易になりました。
1 クエリ 1 ジョブとすることで、安定性と可観測性の両方を確保できたと考えています。
この経験から、BigQuery のスケジュールクエリでは
「1スケジュールクエリにつき 1 SQL 文」で登録する構成が比較的安定して動作しやすいことが確認できました。
⚠️ 注意
※なお、今回の事象はあくまで観測結果および推定に基づくものであり、 すべてのケースで同様に解消されることを保証するものではありません。 同様の現象が発生した際の参考事例としてご覧ください。
まとめ
CloudTrail ログは中間テーブルでARRAY<JSON> として受け取ると安定する
- JSONスキーマ変化による型の不安定さを吸収でき、すべてのログを確実に保存できる。
INSERTとTRUNCATEなどの異なる処理は別クエリとして実行した方が安定する
- スケジュールクエリは1ジョブ1SQLが基本単位であり、異なる処理をまとめると実行時エラーを誘発する可能性がある。
パーティション設計によりクエリコストとスキャン範囲を最適化できる
eventTimeでのパーティション化により、分析時のコスト抑制とレスポンス改善を両立できた。




