
こんにちは!PR TIMES 開発本部フロントエンドエンジニアの岩元 (@yoiwamoto) です。
先日、月間9000万 PV のプレスリリース配信サイト PR TIMES で、もっともアクセスが多い「プレスリリースページ」の実装を、PHP + Smarty + jQuery から Next.js に移行しました。
今回はこれについての詳細や難しかったことなどを共有します。
背景と目的
PR TIMES の Web アプリケーションのフロントエンドは、この数年、必要な部分から随時ページ単位で React 実装へのリプレイスが進んでいる状態で、まだ多くのページでバックエンド生成の HTML + jQuery の実装が残っています。
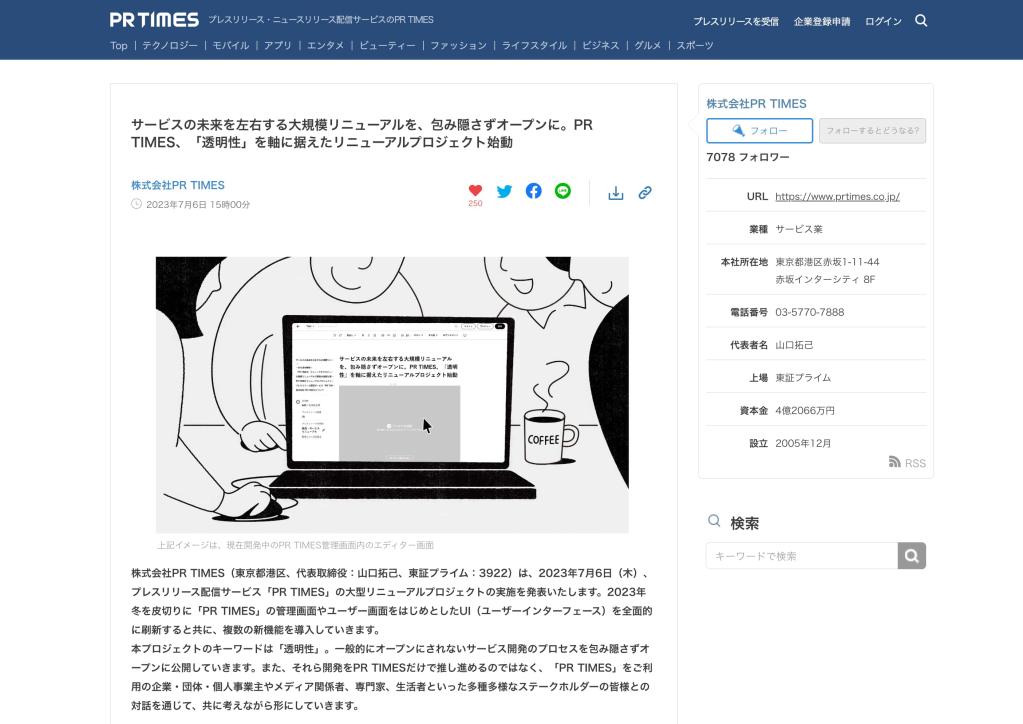
ご利用企業様のプレスリリースを掲載するプレスリリースページ(下スクリーンショット)もその一つで、機能追加や改修のニーズはありながら、大きな変更を行うことが難しい状態が続いていたのですが、今回、UI リニューアルプロジェクトの一環でプレスリリースページでも大きな UI 刷新が行われることになりました。
UI 更新自体がそれほど技術的にヘビーなリリースでないとはいえ、Next.js サーバーの運用の前例が会社としては無い状態で、いきなり全てのトラフィックを新しいサーバーに向けるのはリスクだと考えました。
そのため、予め機能やデザインをそのままにサーバーの移行を完了し、後から UI 更新を行うという流れを取って進めました。
UI リニューアルプロジェクトについては、以下のプレスリリースをご参照ください。

技術選定
アーキテクチャ
これまで、PR TIMES のフロントエンドの React リプレイスでは、企業様が利用する管理画面が大半だったこともあり、アーキテクチャとしてSPA (Single Page Application)の形を取っていました。
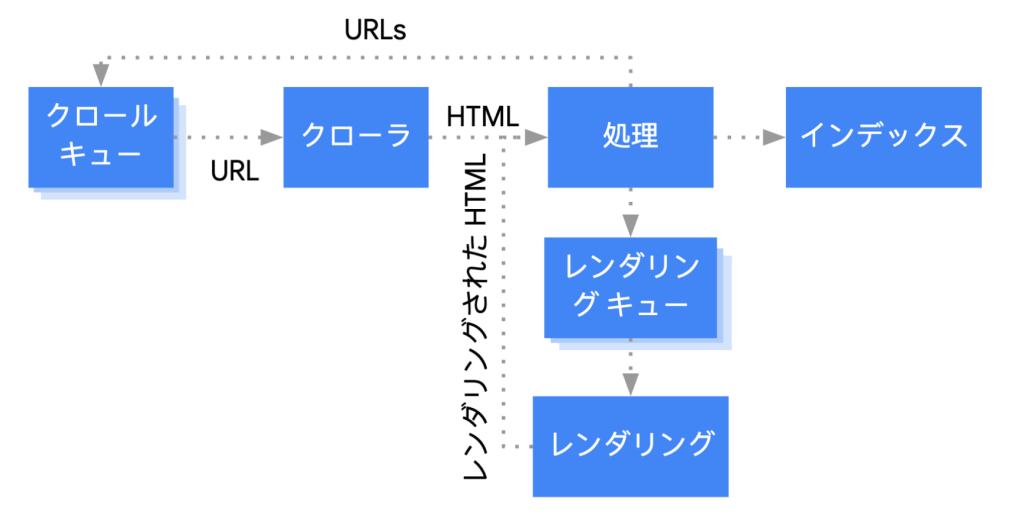
しかし、プレスリリースページは一般に公開されたページであり、パフォーマンスや、検索結果に表示されやすいかなども重要な要件となっていました。現在は SPA であってもクローラが JavaScript を実行するので、データ取得・レンダリング後の HTML が正しくインデックスされますが、レンダリングキューに積まれる前のインデックスの時点でほぼ完全な情報を含んだ HTML になっている SSR の方が、検索結果への反映までの時間の面で通常有利と言われています。
このため、SSR(Server Side Rendering)を前提として設計を行いました。
(https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics?hl=ja#how-googlebot-processes-javascript)

フレームワーク
上記のアーキテクチャ上の要求から、Next.js を採用しました。この選択については、比較的十分に議論されているのと、主題ではないため今回割愛します。
また、App Router ではなく Pages Router を利用しています。これは、安定性や、監視ツールの SDK の対応状況などのためです。
念のため、App Router が Production Ready とは言えない、ということではなく、これらをカバーするのに十分な知見があり、一定コストをかけられるのであれば選択できるものだと思っています。
それと、Next.js はビルトインの Link を使用するとクライアントサイドでページ遷移を行いますが、今回はこれを使用せず、各 URL へのリクエストに対して単に HTML を返すだけにしています。理由としては以下です。
- 各ページのレスポンスが十分に速い。
- ページを跨いで共通のデータの取得(複数回取得されて無駄になるもの)が少ない。
このようなアプリケーションについて、preload によるアクセス量のケアやその他の実装上の複雑性を敢えて持ち込む必要はないと判断しています。
構成
新たに Next.js を稼働させるサーバーを ECS で配置し、Fastly の VCL でリクエストの URL パターンがプレスリリースページのものである時、新しいサーバーに対してリクエストが向くような構成を取っています。以下は構成の簡略図です。
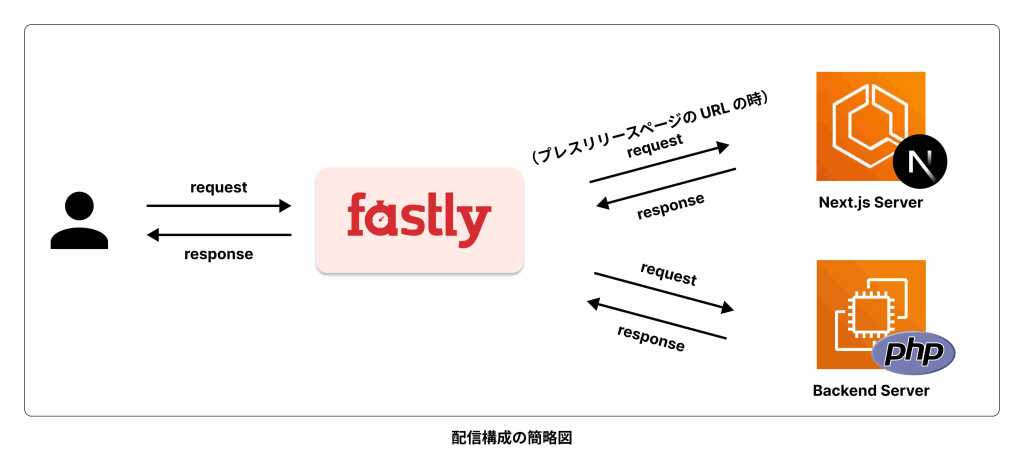
また、DB へは Next.js サーバー(BFF)からはアクセスせず、VPC の内部でバックエンドサーバーに問い合わせる形を取っています。
要点
キャッシュ
Next.js 実装の Web アプリケーションにおけるキャッシュ事情は App Router の登場から大きく変わっていますが、差し当たってこのエントリでは Pages Router のパラダイムを前提とします。
大枠として、公開情報を載せて SSR した HTML を、CDN でキャッシュさせて配信する構成になるのですが、この前提となっているポイントをいくつか書きます。
1. オリジンサーバーにキャッシュを持たない
今回、getStaticProps のような、フレームワークが管理し、サーバーに保持されるキャッシュを使用していません。
Pages Router 時代の配信のベストプラクティスとしては、アクセスごとにリクエストに対して動的な処理(例えば認証情報に依存したデータ取得)を行う必要のない大抵の静的コンテンツのページでは ISR 戦略を取るのが良いとされていました。
具体的には、ある URL に対する初めてのリクエストで regeneration を行い、その HTML を返しつつ結果をサーバー上に保持し、revalidate に指定した TTL が切れるまでの間、それ以降のリクエストに対してもそのキャッシュを返すのみ、という振る舞いにするものです。
これに従うとプレスリリースページは、一部動的なコンテンツが存在するものの、ほとんどが静的コンテンツなので ISR を採用するのが正しそうに見えますが、そうしていない理由としては、以下があります。
➢ CDN と多段キャッシュにしたくない
キャッシュ操作の柔軟性は間違いなく Fastly の方が高く、CDN とオリジンの多段キャッシュにする意味もないので、するなら Fastly に任せたいという意図があります。
例えば生成された HTML のキャッシュは、後から追加された On-Demand Revalidation の機能で、自前でエンドポイントを用意してそれを叩けば更新を要求することが可能ですが、いわゆるソフトパージに近いもので、バックグラウンドで regeneration が完了して新たなキャッシュが作られるまでの間、stale が返却されることになります。

その他、Fastly ではサポートされているような Surrogate-Key パージなども、おそらく不可能ではないですが、自前で組むには一定複雑な仕組みを作る必要があり、ハードルは高そうです。
➢ 複数台サーバーでキャッシュを同期する簡単な方法がない
生成された HTML のキャッシュはファイルシステムに保持されるため、オリジンが複数台のサーバーの構成で、単純には整合性が保証できません。
上記のような理由で、SSR の具体的な実装としては getServerSideProps を使用しており、オリジンリクエストが飛んだ際には常に最新のデータが利用されることになります。
また、getServerSideProps ではメインのバックエンドサーバーにデータ取得のリクエストを行いますが、これについてもキャッシュは使用されていません。
ただ、SSR はシンプルなページでも一定重い処理なので、revalidate(オリジンリクエスト)ができるだけ非同期に行われるよう、キャッシュ設定としては max-age に加えて stale-while-revalidate を指定しています。
2. フロントエンド側のミスによって情報漏洩が生じうる構成を初めから取らない
認証が必要な情報の扱いについて、メインのバックエンドサーバー側で正しく取り扱っていれば漏洩が起きえないような構成を理想としました。
PR TIMES のプレスリリースでは、メディアユーザーと呼ばれる、報道関係者等のユーザー向けの限定コンテンツ(PDF ファイルやテキストなど)を指定することができたり、ページ自体をメディアユーザーのみに公開する設定ができたりするのですが、プレスリリースページでは、このような非公開情報については部分的に SSR を避け、クライアントサイドからデータ取得を行い CSR しています。
表示される情報は個別のユーザーによって違うわけではなく、メディアユーザーという一定規模のユーザー層に対して同一です。そのため、表示速度を最適化しようとする場合、例えばメディアユーザー限定のコンテンツもキャッシュしておいて、リクエストしてきたのがメディアユーザーであればそれを返す、というキャッシュの管理が考えられます。
これはエッジでリクエストヘッダの JWT を検証して切り分けるくらいのことができれば実現できます。
ただしこの仕組みでは、例えば BFF で限定コンテンツの判定処理にバグが生じ、限定でないかのようなレスポンスで CDN にキャッシュされてしまったり、あるいは JWT の検証処理に誤りがって限定コンテンツが公開されてしまったりする、などのリスクが生じます。
もちろん、いずれも看過できない(管理しきれない)ほどのリスクではなく、場合によっては導入されることもあるかと思いますが、部分的にな CSR でも十分に速い LCP が保てる中でこのような手法を取るのが妥当とは言えないと判断しました。
配信割合を刻んでの段階リリース
アクセス量が非常に多いページで、Next.js サーバーの運用が社内では初めてだったので、主に負荷の様子を見る目的で段階リリースを行いました。Fastly の Director 機能の Random を使用しています。

Terraform では、以下のように director を記述し、
director {
name = "prtimes_production_random_director"
backends = [
"prtimes-production-alb",
"prtimes-next-alb"
]
// ...
}それぞれの backend に weight を指定します。下記は 20% リリース時の例。
backend {
name = "prtimes-production-alb"
weight = 4
// ...
}
backend {
name = "prtimes-next-alb"
weight = 1
// ...
}New Relic で、アクセス量、ブラウザ到達比率、CPU・メモリ使用率、HIT 率、API のレスポンスステータスなどを見るダッシュボード、および一部のメトリクスで Slack へのアラートを設定して監視しつつ、スペックや台数を調整しながら 100% まで割合を上げていきました。

また、通常、機能が変わるようなリリースを段階リリースする場合、個々のユーザーの体験がリクエストごとに変わってしまうことがないよう、Cookie を付与してセッションスティッキーにすることも考えられますが、今回は機能やデザインはそのままにリプレイスしているので、そのような仕組みにする必要がありませんでした。
難しかった・ハマったところ
旧サーバーが Set-Cookie を返すため HIT-FOR-PASS が生じる
一定の割合のリクエストを新しいサーバーに流すようにしてからも、しばらくヒット率が非常に低い状態が続いていたので、調査のため、Fastly のアクセスログから、response_state が HIT ではないアクセスの response_state がどうなっているかを確認したところ、ほとんどが MISS ではなく PASS であることが分かりました。
MISS はキャッシュが存在しなかった時の state ですが、PASS はキャッシュができなかった時です。
VCL を見つつ旧プレスリリースページの挙動を確認したところ、なんらかのユーザーでログインしている状態で GET を行うと、Set-Cookie ヘッダが返ってしまっていることが分かりました。通常、Set-Cookie の付いたリクエストはキャッシュせず、PR TIMES の VCL でも、VCL の boilerplate にあるように、Set-Cookie があれば PASS をする設定になっていました。
sub vcl_fetch {
#FASTLY fetch
// ...
# If the response is setting a cookie, make sure it is not cached
if (beresp.http.Set-Cookie) {
return(pass);
}
}Fastly では、ある URL に対して PASS でレスポンスしてしまうと、HIT-FOR-PASS と呼ばれるオブジェクトが作成され、一定時間、該当 URL について vcl_recv で PASS されたかのような振る舞いになります。つまり、新しいプレスリリースページはキャッシュ可能なコンテンツであるにも関わらず、同じ URL で旧プレスリリースページへのアクセスがあると、しばらくは PASS し続ける状態になっていました。
これは、どちらにしろ PASS になる URL について、同時に複数ユーザーからのアクセスがあった際に、複数のオリジンリクエストを並行で行うために必要な仕組みですが、今回のような、同じ URL に対してランダムに別のサーバーを割り当てる特殊なケースでは少し厄介でした。
旧サーバーから Set-Cookie を返さないようにすることも考えられましたが、影響範囲が広いことと、そもそも今回の目的は旧サーバーのレスポンスもキャッシュできるようにすることではないことから、HIT-FOR-PASS を作成しないためのワークアラウンドを取るようにしました。
サポートの方に教えていただいたのですが、PASS する場合でも、以下のように beresp.cacheable に false が指定されていると、HIT-FOR-PASS が作成されません。
# If the response is setting a cookie, make sure it is not cached
if (beresp.http.Set-Cookie) {
set beresp.cacheable = false;
return(pass);
}今回は、差し当たって移行が完了するまでの間、プレスリリースページの URL へのアクセスの時、beresp.cacheable を false にすることで、新しいプレスリリースページのレスポンスがキャッシュできない問題に対応しました。
PC / SP でのキャッシュの切り分け
旧プレスリリースページのフロントエンド実装はレスポンシブではなく、PC と SP で HTML の構造、表示する項目が大きく異なっていました。
今回のリプレイスの方針上、Next.js でもリクエストの User-Agent を見て PC / SP で異なる HTML をレンダリングすることにしたのですが、同一 URL に対して複数のキャッシュを持つ場合、Vary で切り分ける必要があります。
まず、User-Agent からのデバイス判定処理をアプリケーションで持たなくて済むよう、VCL で使用できる変数を使用して PC / SP をリクエストヘッダに指定し、
sub vcl_recv {
#FASTLY recv
// ...
if (client.platform.mobile) {
set req.http.X-Device-Type = "mobile";
} else {
set req.http.X-Device-Type = "desktop";
}
}Next.js からのレスポンスヘッダの Vary に X-Device-Type を含めれば良いので、getServerSideProps 内で以下のようにヘッダを操作します。
export async function getServerSideProps(ctx) {
ctx.res.appendHeader('Vary', 'X-Device-Type');
// ...
}これで切り分け処理としては問題ないのですが、数%リリースしている段階で、「PC でアクセスしているのに SP 用のページが表示される」という不具合が1日に数件報告されるようになりました。
現象が起こった際の User-Agent を指定して叩いても正しいキャッシュが返ってくるなど、再現が不安定で特定に時間がかかったのですが、蓋を開けてみれば原因は、上記の X-Device-Type の set 処理を if (!req.backend.is_shield) ブロックの中に書いてしまっていることでした。
つまり、ある URL のキャッシュが Edge POP に存在していた時、Edge POP では X-Device-Type ヘッダの指定が行われていないため、Vary が効かず、デバイスを問わずにキャッシュが返却されてしまっていた、という形になります。
PR TIMES の Web サイト配信用の Fastly サービスではオリジンシールドを有効にしていて、vcl_recv サブルーチン上では backend 指定、不要な Cookie の削除など、Edge POP で行う必要はない多くの処理がこのブロックの中に書かれており、自分は初めて VCL を触るのでなんとなくここに追記してしまっていました。
今後初めて VCL を触る方は、ぜひお気をつけください。
移行結果
今回、開発速度向上のためにリプレイスは必須であり、パフォーマンス等の向上自体は Non-Goal なのですが、副次的に改善されている部分もあります。
影響したのは主に実装詳細の変化だと思っていて、昨今一般的になってきたアクセシブルなマークアップで実装されていること(至らない点もあります)や、これらがある程度考慮されたデザインシステムコンポーネントが利用できるようになったことなどがありそうです。
New Relic でエンドユーザー端末上での各種数値を収集しており、下の画像はその Web Vitals のサマリです。
まだまだ改善の余地があるものの一定安定しており、この画面にはないですがエラーレートも低い水準で配信することに成功しています。

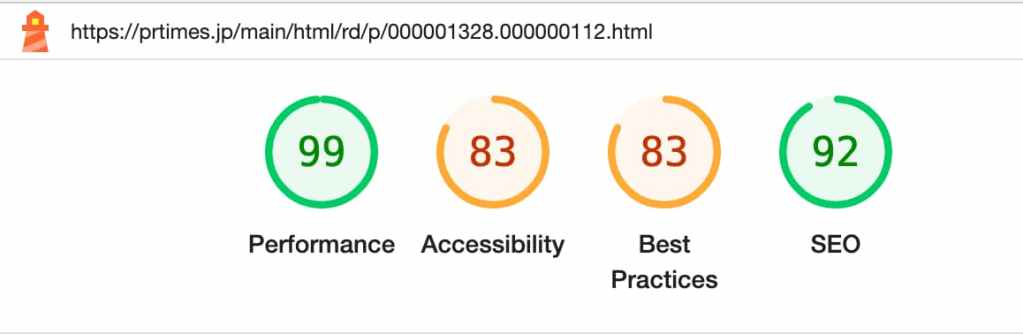
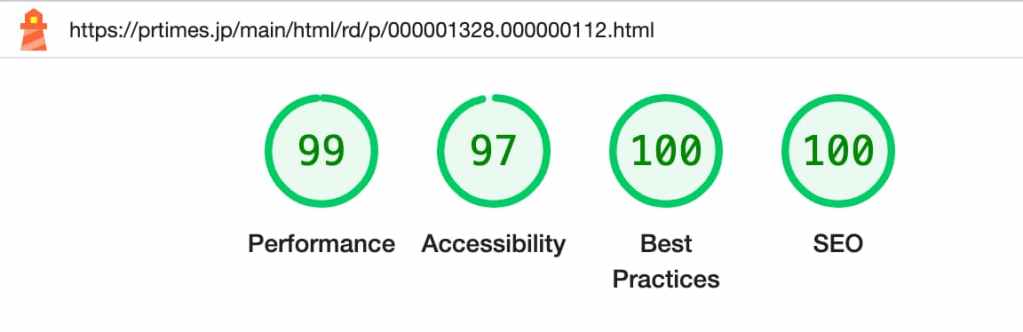
また、目安程度にはなりますが、UGC 部分で画像を14件含むプレスリリースのページで Lighthouse スコアを比較したところ、特に Accessibility や Best Practices が明確に改善されていることが確認できました。
今後
今回のリプレイスで、まだ達成できていないものがいくつかあります。
データ更新をトリガーにキャッシュをパージする仕組みの整備
キャッシュヒット率についていくつか改善を行ったことを書きましたが、実はそれらの対応を行い、100%リリースされた今でも、ヒット率は 25~40% ほどと低いです。
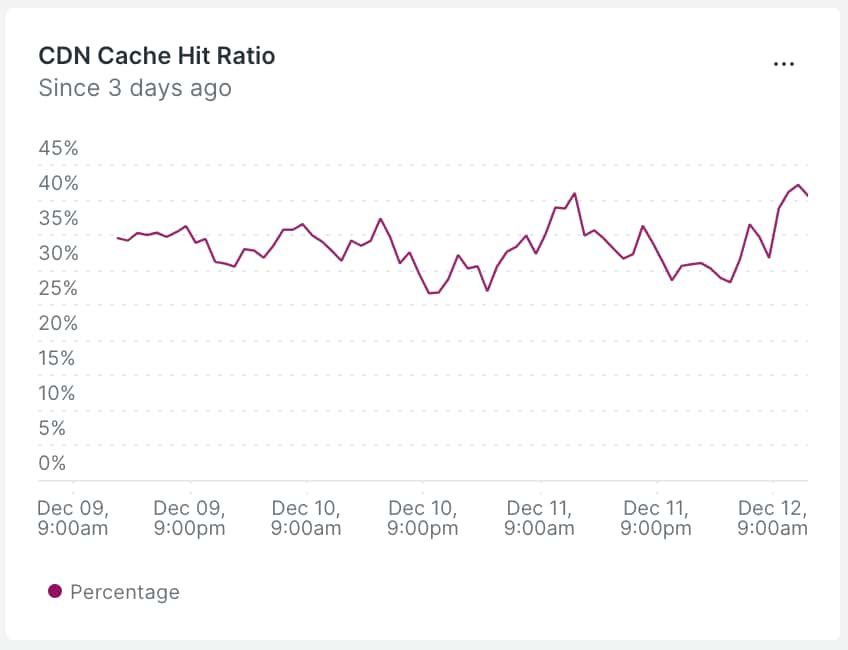
主な理由として、単純にキャッシュの TTL が短いです。Surrogate-Control の設定値は以下なので、オリジンリクエストから60秒間はキャッシュが返され、その後120秒以内のリクエストに対しては stale を返してバックグラウンドで validate が行われる、という形になります。
Surrogate-Control=max-age=60, stale-while-revalidate=120当日に配信されたプレスリリースのようにアクセスが集中している URL はこれでもうまくキャッシュがヒットしますが、PR TIMES サイト上には現時点で100万件以上のプレスリリースが掲載されており、前日以前のアクセスが集中しない URL でも、全体で見ると十分に多く、それに対しては60秒の TTL は短すぎると言えそうです。
これを伸ばすためには、先に、プレスリリースの情報を更新したり、非公開にする「取り下げ」などの操作が行われた時にキャッシュをパージするシステムを整備する必要があります。
その仕組みで変更が全てカバーできれば TTL をほぼ自由に伸ばせるのと、変更の反映速度が速い方がお客様の体験も良いため、次の取り組みたいタスクになります。
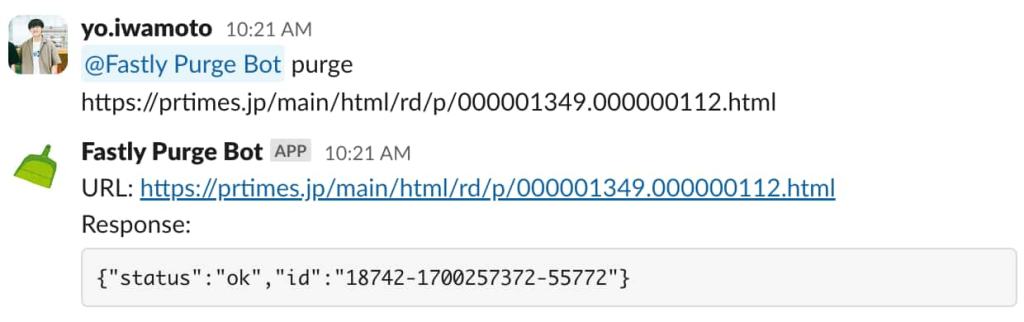
取り急ぎ、お問い合わせの対応時や取り下げなど、すぐにデータが更新したい時に誰でもキャッシュをパージできるよう、Slack bot でのパージ方法を社内に共有しています。(もちろん、オペレーションに負担をかける形になってしまうので、一時的な運用です)
これは、QA などで確認前にキャッシュを破棄する用途で先に実装した社内ツールで、URL ページの他、サロゲートキーパージなどに対応しています。

終わりに
実はこの 100% リリースが完了するまでの間に、同じ Next.js アプリケーションでの実装で検索ページのリプレイスが行われたのですが、それも含めて社内では初めての Next.js サーバー導入事例だったので、前例が作れたことは大きかったと思います。
Next.js 移行と言いつつ JavaScript の話がほとんど出てこないエントリになってしまいましたが、どなたかの参考になれば幸いです。







