
こんにちは。2024年4月に新卒で入社したバックエンドエンジニアの岩瀬(@gantaso4704)です。
今回は、複数あるOpenSearchを統合してコスト削減をした話について書いていこうと思います。
背景
現在、Webクリッピングでは記事データをOpenSearchに保存し、検索機能で利用しています。

Webクリッピングとは、さまざまなサイトから記事をクロールし、ユーザーが設定したキーワードが含まれる記事をクリップすることで、メディア露出の調査や分析を行えるWebアプリケーションです。

Webクリッピングでは、二種類の OpenSearch を使い分けていました。
「短期OpenSearch」は直近の一週間以内の検索に対応し、バッチ処理や新しい記事を検索する際に利用されています。 一方で「長期OpenSearch」は、それ以降の過去データを検索するために使われていました。
しかし、今年の春頃に「長期OpenSearch」の検索速度が大幅に向上したことを受け、「長期OpenSearch」だけで「短期OpenSearch」の処理を代替できないかという仮説が生まれました。
OpenSearchの検索速度向上に関して詳しくはこちらをご覧ください。

もしその仮説が正しければ「短期OpenSearch」を廃止してOpenSearchの運用費用を削減することができます。
統合のための調査
統合に着手する前に、「短期OpenSearch」へのリクエストを「長期OpenSearch」に振り分けた場合の遅延と、それがユーザーにどれほどの影響を及ぼすかを検討する必要がありました。
正直なところ、この部分には最も苦心しました。「短期OpenSearch」と「長期OpenSearch」の間には
- インスタンスタイプの違い
- 現在処理しているリクエスト量の差異(短期は長期の100倍程度)
- 格納されているドキュメント数の多さ(「長期OpenSearch」の方が多い)
といった多くの相違点があり、事前に遅延の程度を見積もるのは時間と労力がかかる作業でした。
さらに、ステージング環境はコスト削減のため本番環境と異なる構成となっており、一つのインスタンスで「短期OpenSearch」と「長期OpenSearch」の両方の処理を行っていたため、参考にすることはできませんでした。
そこで、少し方針を変更しました。統合によって「長期OpenSearch」の負荷が過度に増大した場合でも、インスタンスのスペックを向上させれば対応できるだろうと見込んで、「短期OpenSearch」に対するリクエストを徐々に「長期OpenSearch」へ移行するように段階的に変更を加えていくことにしました。
統合の途中で「長期OpenSearch」のレスポンスが極端に遅れたり、CPU使用率が危険な水準に達した場合には、「長期OpenSearch」のスペックを上げるという判断を下すことにしていました。
統合作業
統合を進めるにあたって、まずはタスクの切り分けと、どのような順序で作業を進めるかを考慮しました。
私は「短期OpenSearch」へのリクエストが多い機能を優先して「長期OpenSearch」に統合するのが良いと考えていました。
その理由は、完全な統合が可能か未だ不明な状況だったため、「長期OpenSearch」への影響が大きいタスクの統合を問題なく乗り切れば、残りのタスクもほぼ確実に進められるだろうと考えたからです。
逆に言えば、初期段階で大きな問題が発生すれば、その時点で統合を一時中止する判断に迅速に至れるため、時間を節約できます。
加えて、チームリーダーから「ユーザーへの影響」と「リカバリのしやすさ」を考慮するようアドバイスを受けました。
この新たな視点は私には欠けており、ユーザーのことを常に考える重要性を新たに理解することができ、非常に勉強になりました。 これらの観点を踏まえ
「リクエスト数が多い」かつ「ユーザー影響が少ない」かつ「迅速にリカバリ可能なもの」
という基準でタスクの切り分けと、統合の実行順序を決定しました。
統合作業を行っていく
実際に統合作業を進める中で、コードの変更自体は非常にシンプルなものでした。
ほとんどの場合、OpenSearch に関連するサーバーのタイプは OpenSearchServerType というパラメータを使って switch 文内で判定されており、そこで「短期OpenSearch」と「長期OpenSearch」の使い分けを行っていました。したがって、必要な変更は switch 文を取り除き、条件判定なしで直接 return するようにコードを修正するだけで済みました。
switch ($openSearchServerType) {
case OpenSearchServerType::OPEN_SEARCH_FAST:
$index = OpenSearchIndexConfig::ALIAS_NAME_FOR_CURRENT_INDEX_OF_OPEN_SEARCH_FAST;
$host = OpenSearchIndexConfig::SEARCH_FAST_HOST;
return $this->openSearchContentRepository->search($searchQuery, $index, $host);
case OpenSearchServerType::OPEN_SEARCH:
$index = implode(',', ArticleSearch::getIndicesForSearchingBasedOnDateTimeRange($startDate, $endDate));
$host = OpenSearchIndexConfig::SEARCH_HOST;
return $this->openSearchContentRepository->search($searchQuery, $index, $host);
default:
throw new InvalidArgumentException("Failed to identify the OpenSearch server to search contents");
一部アーキテクチャの古いコードが残っており、それらのコードの統合作業は少し大変でしたが、インフラの変化に対応しやすいコードを書くことの重要性をより強く実感することができました。
謎の検索リクエスト
順調にタスクは進んでいき、「短期OpenSearch」への全ての検索リクエストを「長期OpenSearch」に統合することに成功しました。しかし、CloudWatchのメトリクスを確認すると、どうやら約30分に2回の検索リクエストが送られているということが明らかになりました。
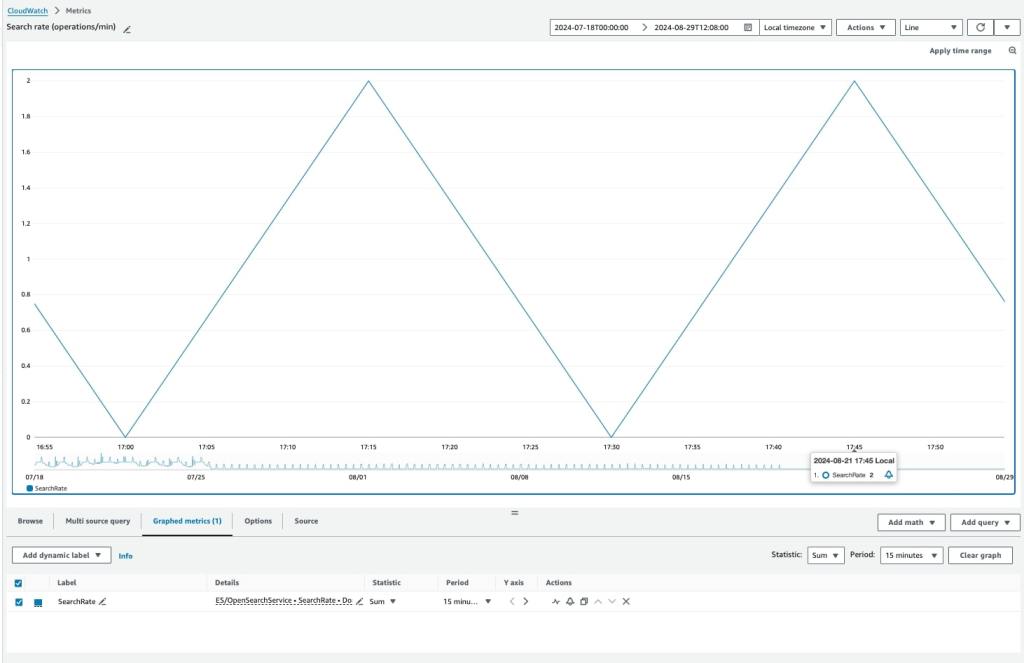
「短期OpenSearch」がまだ使用されている箇所がないか、もう一度徹底的に確認しましたが、疑わしい箇所は一切発見できず、そもそも30分ごとに行われると思われるバッチ処理など、チームメンバーの誰も知らないという状況でした。
さらに、CloudWatch Logs 内の Search slow logs でのログ出力を全て含むように設定を見直しましたが、それに関連するログは依然見つかりませんでした。
どうしても解決策が見出せなかったので、AWSサポートに問い合わせたところ、サービス側でシステムインデックスへの検索リクエストが30分ごとに自動で行われていることが原因であることが明らかになりました。
とりあえず一安心して、次の統合作業に取り組むことができました。
またしても謎のリクエスト
その後、「短期OpenSearch」へのドキュメントのUpsert処理と、一週間以上過去のドキュメントをDeleteするバッチを廃止し、ついに、全ての処理の統合が何事もなく完了しました!
と思って再度CloudWatchを確認したところ、未だリクエストが送られていることが確認でき、絶望しました。 というのも、Upsertの処理を止めた時点で「短期OpenSearch」へのデータ更新は止まっており、もしこれらのリクエストがユーザーに影響するのものであれば、ユーザー側に最新のデータを提供できていないことになるからです。

ですが、やはり思い当たる節がなかったので、「これはもしやまたAWSの仕様によるものなのでは?」と思い、念のためもう一度 AWS サポートへ問い合わせを行いました。
サポートからの返答は予想していた通りで
「ヘルスチェックなどの理由で、AWS システムが内部的に継続的に対象ドメインへリクエストを送信しており、ユーザー側からのリクエストがない場合でも、クラスターのヘルス状態を示す HTTP requests by response code の統計にはリクエストが記録される」 というものでした。
とりあえず一安心して、「短期OpenSearch」の削除を進めても問題ないだろうとは思いましたが、すべてのリクエストがAWSの仕様によるものだと完全に断言することはまだできてませんでした。
監査Logを有効にする
そこで、念には念を入れてOpenSearchの監査Logを有効にして、具体的なリクエストの内容とその送信元を確認することにしました。
監査Log有効化の手順としては、こちらのAWSのドキュメントを参考に、以下のようにして行いました。
- Amazon OpenSearch ServiceでFine-grained access controlを有効にする
- Amazon OpenSearch Serviceから監査Logを有効にする。
- OpenSearch Dashboardで監査Logを有効にし、Logの出力の設定を行う
3のLogの出力の設定に関しては、可能な限り詳細な情報を得たいと考え、ほとんどの項目を「Enabled」に設定しました。

このようにして出力させたLogを、CloudWatchのLogs Insightを用いて分析しました。
リクエストのPathを確認
filter @logStream in [
'logStreamName'
]
| stats count(*) as requestCount by audit_rest_request_path
アプリケーション側で用いている _search や_count などのAPIは使われていないことが確認できました。
リクエスト元の確認
filter @logStream in [
'logStreamName'
]
| stats count(*) by audit_rest_request_headers.Host.0
ほぼ全てがlocalhostからのリクエストになっており、先ほどのリクエストはOpenSearch内部の処理であることがわかりました。
「短期OpenSearch」の削除
監査ログの分析結果を踏まえ、このまま「短期OpenSearch」を削除してしまっても問題ないだろうと判断し、無事削除作業を実行することができました。
削除後もシステムは引き続き正常に機能していることが確認でき、一安心です。
最後に肝心の「長期OpenSearch」のメトリクスを見ていこうと思います。
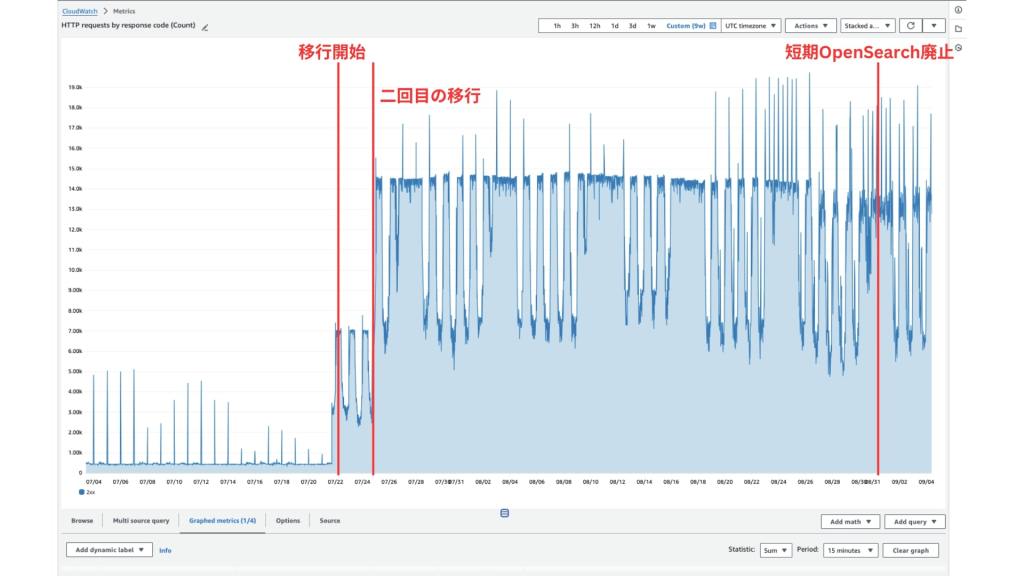
HTTPリクエスト数
検索レイテンシ(合計)

HTTPリクエスト数を見てみると、初回、二回目の統合作業で大半のリクエストの移行が完了していることがわかります。また、少し不思議なのですが、二回目の統合作業が完了したタイミングで検索レイテンシが低い値で安定するようになりました。
これはあくまで推測ですが、頻繁にリクエストが行われるようになったことで、常に暖機運転するようになり、結果としてレイテンシが安定したのではないかと考えています。
最後に
今回紹介した「長期OpenSearch」と「短期OpenSearch」の統合というタスクは、自分が配属後初めて担当したタスクであり、終了まで想定よりかなり時間がかかってしまいましたが、諸々の調査を通してOpenSearchのことはもちろん、Webクリッピングに対してもコードベースのみならずサービスとしての解像度がかなり深まりました。
また、いろいろなタスクにチャレンジして、ブログで皆さんに共有できればと思います。
最後までご覧いただき、ありがとうございました!







