
皆さんこんにちは!PR TIMESの開発部のThaiです。今回はどうやってOpenSearch検索速度を改善したかについて話します。
はじめに
現在、Webクリッピングでは記事データをOpenSearchに保存して検索機能で使っています。

Webクリッピングとは、さまざまなサイトから記事をクロールし、ユーザーが設定したキーワードが含まれる記事をクリップすることで、メディア露出の調査や分析を行うことができるWebアプリケーションです。

Webクリッピングではユーザーが複数のキーワードを同時に検索できるようになっており、キーワードの長さや文字種類などの制限もありません。ユーザーが任意のキーワードを入力して検索できる機能を提供しています。その自由度の高さはユーザーにとって非常に便利ですが、同時にシステムに大きな負担をかけています。ユーザーが非常に長いキーワードや複数のキーワードを一度に入力すると、システムは複雑なクエリを処理する必要があり、これにより高負荷で動作することになります。そのせいで、検索速度が著しく低下し、時には30秒に設定されていたタイムアウトが発生することもありました。
一般的な手法を試す
まずはOpenSearchの検索速度を向上させる一般的な手法をいくつか使ってみました。
シャード数を変更
この手法は、シャードの容量を理想的な範囲に最適化することで、検索速度を向上させる可能性があるため、よく推奨されます。
シャード数を選択することの全体的な目標は、クラスター内のすべてのデータノード間でインデックスを均等に分散させることです。ただし、これらのシャードは大きすぎたり多すぎたりしてはいけません。一般的なガイドラインとして、検索レイテンシーが主要なパフォーマンス目標であるワークロードではシャードのサイズを 10~30 GiB、ログ分析などの書き込みが多いワークロードでは 30~50 GiB の範囲に維持することをお勧めします。
https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/sizing-domains.html#bp-sharding
シャード数を30から36や50などに上げてみましたが、シャード数をもっと増やしてみても複雑なクエリの場合には検索速度がそれほど変わりませんでした。
クラスタのスケーリング
検索クエリによる Read スループットは変わらず、スロットリングは解消できない可能性があります。このため、優先的にEBSボリュームのスループットをもっと増やし、データノードを追加することもやってみました。ですが、この手法で行っても解決できませんでした。
参照: https://repost.aws/ja/knowledge-center/opensearch-scale-up
クエリ修正
クエリが複雑すぎる場合、インデックスを最適化しても効果は薄いです。そのため、インデックスの最適化よりもクエリ改善がベストです。しかし、システムの現在の技術仕様では、クエリの修正には多くの時間がかかり、私たちの顧客はそれを望んでいません。クエリの改善は必要ですが、現在の検索の遅さを迅速に解決できる手法が必要です。
スキャンされるシャード数を減らすと検索速度が速くなると発見した話
以前はWebクリッピングでは2つのインデックスがありました。
- 短期インデックス
-
これはバッチ処理や最近の新記事を検索するためのインデックスです。
- ドキュメント数: およそ120万件
- 期間範囲: 1週間
- 長期インデックス
-
これは過去の記事を検索するためのインデックスです。
- ドキュメント数: 9000万件以上
- 期間範囲: 1年間
今回の検索速度の問題は長期インデックスの場合のみ発生していました。以下は2つのインデックスの検索結果です。
短期インデックスの場合
# リクエスト
GET /clipping_open_search_fast_content_20231030140359/_search
{
"query": { ... }
}
# レスポンス
{
"took": 83, # <-- 83msしかからなかった
"timed_out": false,
"_shards": {
"total": 2,
"successful": 2,
"skipped": 0,
"failed": 0
},
...
}長期インデックスの場合
# リクエスト
GET /clipping_open_search_content_20231119121700/_search
{
"query": { ... }
}
# レスポンス
{
"took": 21140, # <-- 21秒かかった
"timed_out": false,
"_shards": {
"total": 50,
"successful": 50,
"skipped": 0,
"failed": 0
},
...
}短期インデックスの場合は83msだけかかりましたが、長期インデックスの場合は21sまでかかってしまいました。検索結果を見ると、これらのケースの違いは、検索されるシャード数「_shards.total」だと理解しました。長期インデックスの検索の場合はスキャンされるシャード数およびドキュメント数を減らすことができれば、検索速度を向上することができるかもしれないのでやってみました。
Time-Based Indicesを使う
まずはシャード数を減らすと結果が変わるのかを検証しました。具体的には以前の複雑なクエリを再度実行しましたが、今回は全てのシャードを検索するのではなく、特定の1つのシャードのみを対象に検索してみました。検索速度が早いことがわかりました。
# リクエスト
GET /clipping_open_search_content_20231119121700/_search?preference=_shards:1
{
"query": { ... }
}
# レスポンス
{
"took": 364,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
...
}シャード数を減らすことにより、クエリの速度が大幅に向上することが確認されました。しかし、既存の長期インデックスの構造に対してどのシャードを指定して検索すべきかを知るのは本当に難しいです。そこで Time-Based Indices技術を採用することにしました。これは、大規模で分散されたデータストレージシステムの検索速度を向上させるための効果的な手法です。Time-Based Indicesは、日次、週次、月次でデータを保存するシステムに特に有用です。時間に基づいてインデックスを分割する手法で、特定の時間範囲に関連するインデックスのみをスキャンすることで負荷を軽減し、クエリの速度を向上させることができます。
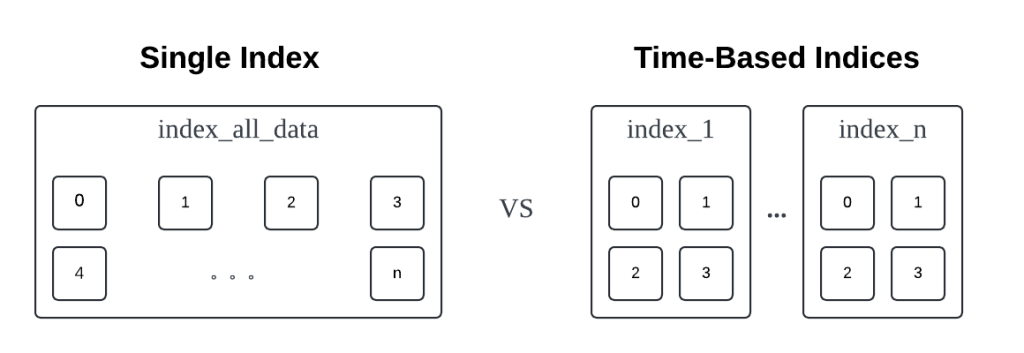
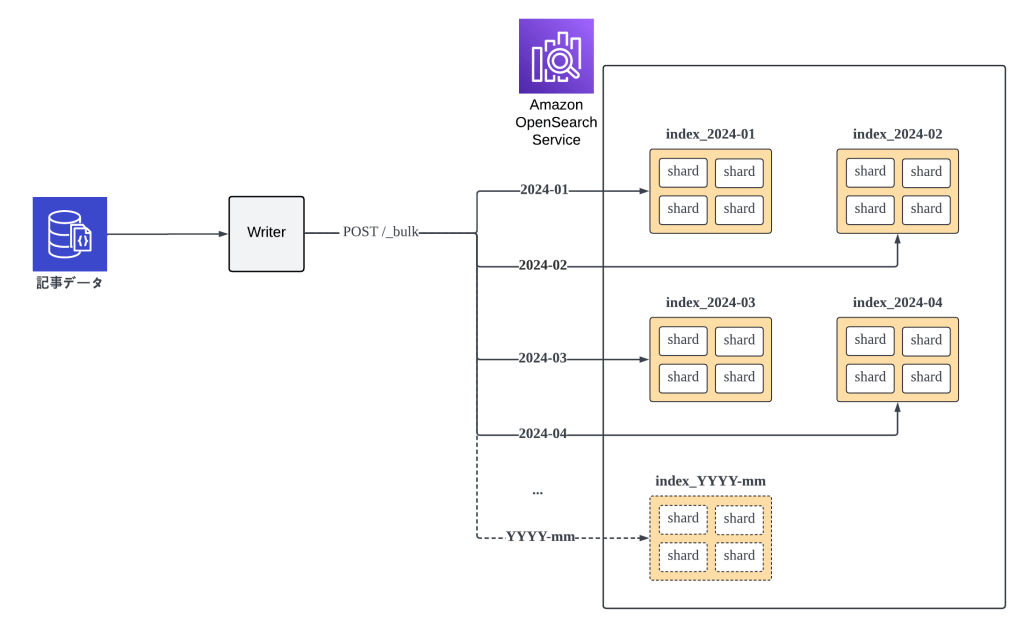
上記のアイデアに基づいて、インデックスを再構築してみました。すべての記事データを1つのインデックスだけに保存する代わりに、各月をそれぞれ個別のインデックスに分割しました。以下はデータの書き込み・読み込みフローです。
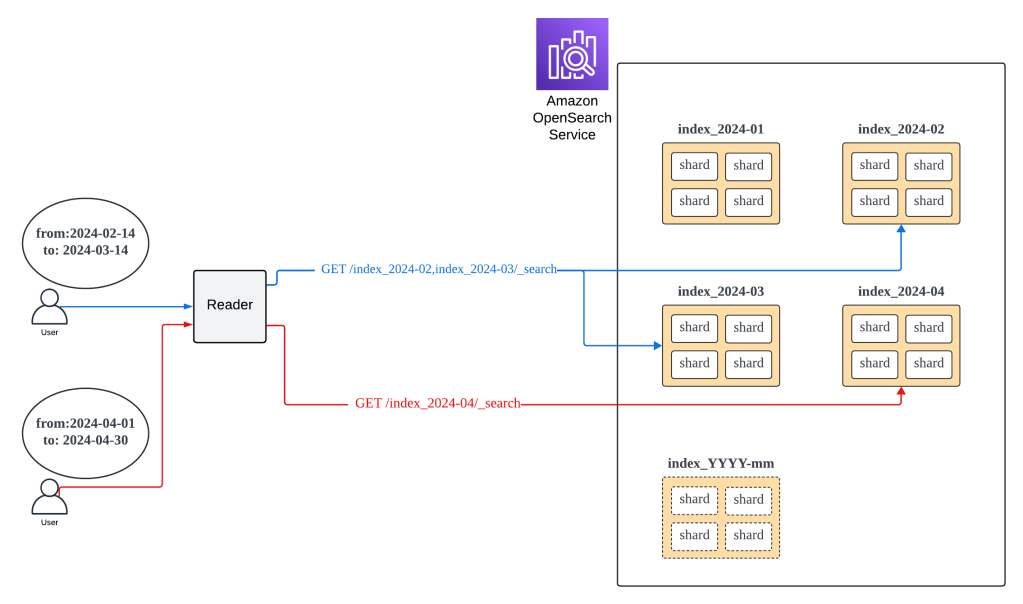
本番リリース後の結果
テストして効果があることがわかりましたので、本番リリースしました。結果は期待通り検索速度が非常に速くなりました。本番リリースして以来検索機能に関するアラートも発生していません。
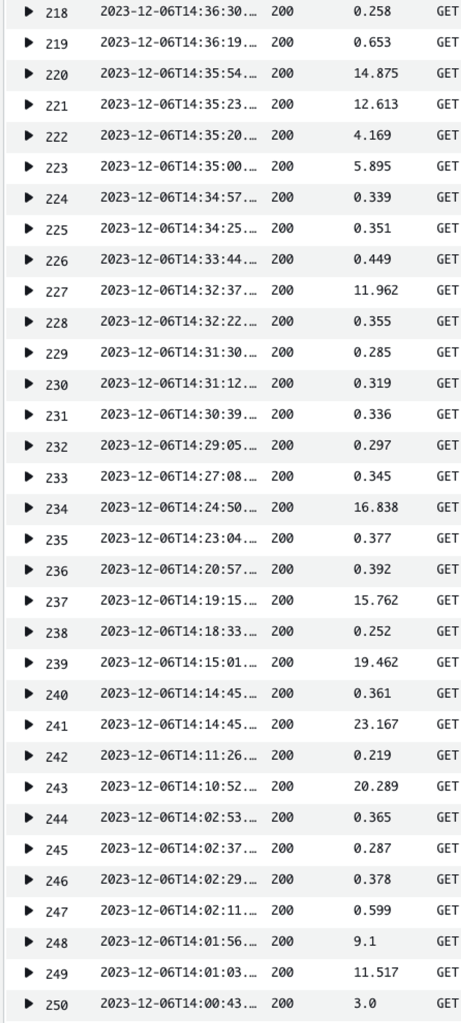
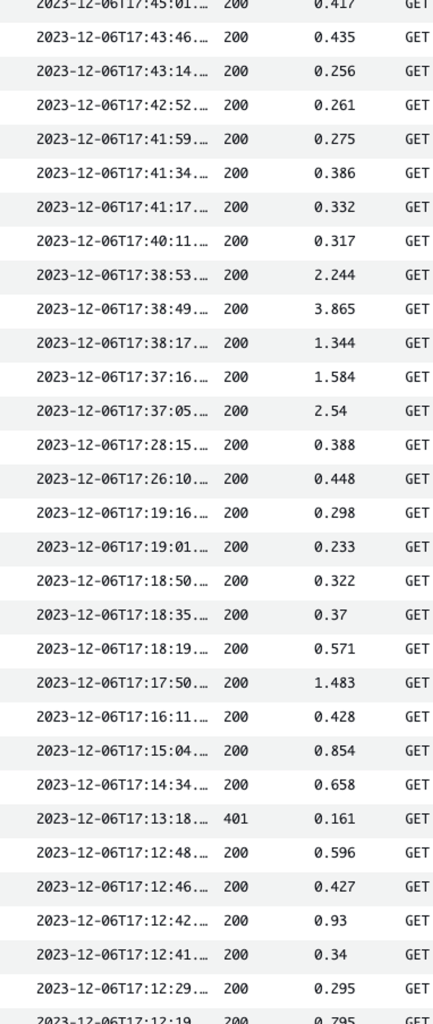
さらにカスタマーリレーションズ部からも、速度が本当に速いとのフィードバックを受けました。これは素晴らしい成果です。


未来向けの他のメリット
検索速度を上げること以外、以下のメリットもあります。
古いデータを削除しやすい
Webクリッピングでは、過去1年以内のデータのみ使うので、一定期間が経過したら古いデータを削除する必要があります。以前のシングルインデックス構造では、以下のAPI(delete-by-query)を使って古いドキュメントを削除することができます。
参照: https://opensearch.org/docs/latest/api-reference/document-apis/delete-by-query/
しかし、上のAPIを実行すると一点注意する必要あります。
When a document is deleted from an OpenSearch index, it is not deleted from the Lucene segment but is rather only marked to be deleted. When the segment files are merged, deleted documents are removed (or expunged). Thus, merging also frees up space occupied by documents marked as deleted.
https://opensearch.org/docs/latest/api-reference/index-apis/force-merge/#deleted-documents
ドキュメントが削除されると、すぐに物理削除されなくて、「物理削除する必要がある」ようにマークを付けるだけです。セグメントがマージされるまで、削除されたドキュメントによって消費されたバイトは回収されません。セグメントマージは定期的に動いているので、勝手に回収されるはずですが、メモリに十分な空きがない場合などはauto mergeが動かずに回収されないことも考えられます。Time-Based Indicesを使用することで、古いデータの削除がより簡単です。データが月ごとに分割されているため(各月が1つのインデックス)、古いインデックスを削除するだけで、データが即座に削除され、そのデータに割り当てられていたメモリがすぐに解放されます。
参照: https://opensearch.org/docs/latest/api-reference/index-apis/delete-index/
シャード数を変更しやすい
データサイズが固定ではありません。後月は前月よりデータ量が多いまたは少ないなら、既存のシャード数の設定が適当ではないかもしれません。その場合はシャード数を調整しなおす必要があります。シングルインデックスの場合はシャード数を更新するならインデックスを全体リビルドしなおす必要があります。データが多いなら時間がかかります。以前、シングルインデックスを全体リビルドして3~4日かかったことがあります。 逆に、Time-Based Indicesの場合は全てリビルドせず、新インデックスのみ更新しますので、時間がかかりません。これにより、将来のスケーリングやパフォーマンス調整が柔軟になります。
何か注意する必要があるのか?🤔
基本的には、この手法はクエリのスキャン対象となるシャード数とドキュメント数を期間に基づいて減少させることで、速度を向上させるものです。そのため、期間が広がるほどスキャンするシャード数が増え、検索速度が遅くなります。これは問題ですが、以下の2つの手法を選択することで改善できるかと思います。
検索期間を制限
検索期間を制限するのは、1つのクエリ内で処理できる最大シャード数を制限することと同義です。これにより、クエリが安全な範囲内で常に動作し、パフォーマンスに影響を与えないようにします。検索期間を試して、いつからいつまで安全に処理できるかを確認することができます。たとえば、3ヶ月、6ヶ月、または1年などの時間枠で制限してテストできます。ただし、検索時間の制限なので、一部のユーザーに好まれないかもしれません。したがって、次の手法がより良いかもです。
Multi-search APIを使う
この方法は前述の原則に基づき、クエリ内のシャード数を減らすことで検索速度を向上させることに焦点を当てます。検索範囲が広すぎる場合はCPUに余裕があるなら、より小さい期間に分けて別々のクエリとして同時に投げたほうが良さそうです。Multi-search APIで実行することができます。
参照: https://opensearch.org/docs/latest/api-reference/multi-search/
これにより、1つのクエリ内のスキャンされるシャード数およびドキュメント数がいつも安全な範囲に保たれます。例えば、2023-05-13から2024-04-02までのデータを検索したい場合は以下のように実装できればと思います。
Search APIを使う場合は一つの複雑なクエリを実行する
GET /index_2023-05,index_2023-06,index_2023-07,index_2023-08,index_2023-09,index_2023-10,index_2023-11,index_2023-12,index_2024-01,index_2024-02,index_2024-03,index_2024-04
{ "query":{ "range":{"time":{"gte":"2023-05-13","lte":"2024-04-02"}}...他の条件...}}Multi-search APIを使う場合は4つのより簡単なクエリに分けて実行する
# 各クエリは特定の範囲(例えば、以下の例では3ヶ月間)の検索を担当する
GET _msearch
{ "index": "index_2023-05,index_2023-06,index_2023-07"}
{ "query": { "range": { "time": { "gte": "2023-05-13", "lte": "2023-07-31"}}...他の条件...}}
{ "index": "index_2023-08,index_2023-09,index_2023-10"}
{ "query": { "range": { "time": { "gte": "2023-08-01", "lte": "2023-10-31"}}...他の条件...}}
{ "index": "index_2023-11,index_2023-12,index_2024-01"}
{ "query": { "range": { "time": { "gte": "2023-11-01", "lte": "2024-01-31"}}...他の条件...}}
{ "index": "index_2024-02,index_2024-03,index_2024-04"}
{ "query": { "range": { "time": { "gte": "2024-02-01", "lte": "2024-04-02"}}...他の条件...}}最後に
初めてOpenSearchのクエリ速度の問題に直面したとき、ちょっと不安でした。大量のデータとスロークエリがユーザーエクスペリエンスと作業効率に影響を与えていました。しかし、Time-Based Indicesを導入することで、クエリの速度が改善されました。複雑なクエリでは以前は数十秒かかっていましたが、今では数秒または1秒未満で処理できるようになりました。今の状況だと効果的な手法だと感じていますが、検索期間が広すぎると速度が遅くなる問題があるのでMulti-searchで改善してみようと思います。さらに後ほどもっと調べてみてより良い手法があれば使ってみます。私にとって今回の検索速度改善はチャレンジでした。そのおかげで色々勉強になりました。そこで、次回のブログでは、私が学んだ他の知識を皆さんに共有したいと思います。どうぞお楽しみに!







