
こんにちは、フロントエンドエンジニアのやなぎ( @apple_yagi )です。
先日、【月間9000万PV】プレスリリース掲載ページの Next.js 移行でやったこと、という記事が公開されました。こちらのブログの最後に軽く触れられていますが、プレスリリース掲載ページより前にキーワード検索ページのNext.js移行を行っていました。

本エントリーではキーワード検索ページをNext.js移行したモチベーションなどは割愛させていただきますが、移行後にキーワード検索ページで実装されている無限スクロールのUX改善を行ったのでどのように取り組んだのか紹介します。
Next.jsに移行した初期の実装
Next.jsに移行した初期の実装ではgetServerSidePropsで検索結果の1ページ目を取得し、そのデータをTanstack Queryにhydrateするといった形で実装しました(この実装方法自体はUX改善後も変わりません)。
import {
dehydrate,
type DehydratedState,
QueryClient,
Hydrate
} from '@tanstack/react-query';
export const getServerSideProps = async ({req, res, query}) => {
const {search_word: searchWord} = query;
const queryClient = new QueryClient();
const searchResultResponse = await getSearchResult({searchWord, page: 1});
await queryClient.prefetchInfiniteQuery(
['searchResult', searchWord],
() => searchResultResponse.data,
);
if (searchResultResponse.data.total === 0) {
res.statusCode = 404;
}
return {
props: {
searchWord,
dehydratedState: dehydrate(queryClient)
}
}
}
export default function Page({
searchWord,
dehydratedState
}: InferGetServerSidePropsType<typeof getServerSideProps>) {
return (
<Hydrate state={dehydratedState}>
<Component searchWord={searchWord} />
</Hydrate>
);
}1ページ目をgetServerSidePropsでデータ取得(Server Side Rendering)をしている理由は主に2つあります。
1つ目の目的は、検索結果が0件の場合にHTTPステータスコード404を返すことです。GoogleのSEOにおいて、コンテンツが存在しないページでは200を返すべきではありません。これはReact + Viteの構成でも可能でしたが、以下の図のように2重でOpenSearchと通信する必要があるため、Next.jsでステータスコードを返すようにしました。
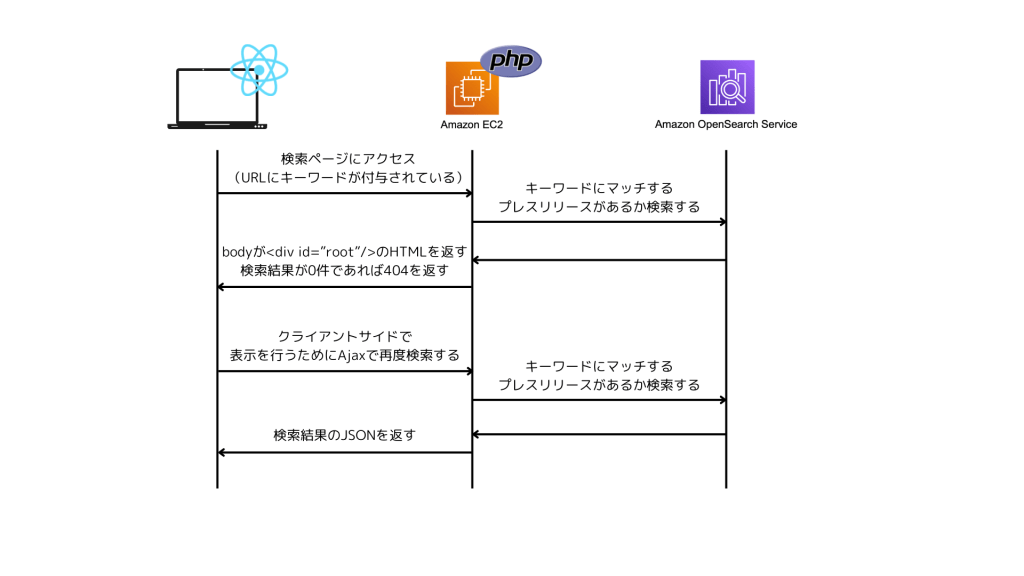
2つ目はコンテンツの表示を速くするためです。上記の図にもあるようにReact + Viteの構成を取った場合、OpenSearchに2回アクセスする必要があるため、ユーザーに検索結果を表示するのが遅くなってしまいます。そのため、Server Side Renderingを行い、OpenSearchへのリクエストを一回で済むようにしました。
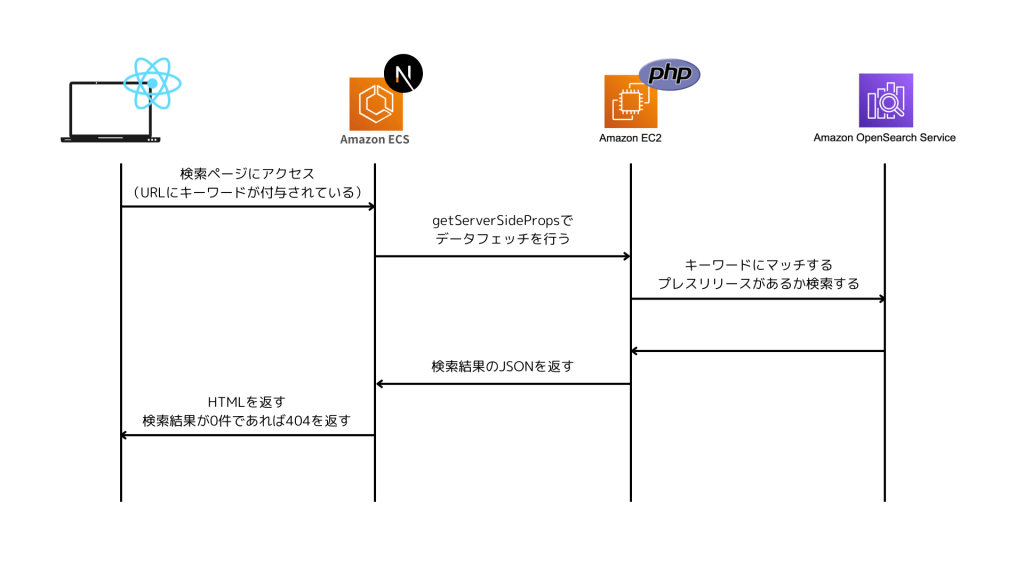
2ページ目以降はuseInfiniteQueryを使用してクライアントサイドでデータを取得し、無限スクロールのUIを実装しています。
const useSearchResult = () => {
const searchWord = useSearchWord();
return useInfiniteQuery({
queryKey: ['searchResult', keyword],
async queryFn({pageParam}) {
const response = await getSearchResult({
searchWord,
page: typeof pageParam === 'number' ? pageParam : 1,
});
return response.data;
},
getNextPageParam(data) {
if (data.currentPage < data.lastPage) {
return data.currentPage + 1;
}
return undefined;
},
retry: false,
});
}
const SearchResult = () => {
const {data, fetchNextPage, hasNextPage} = useSearchResult();
return (
<div>
<ul>
{data?.pages.map((pressRelease) => (
<li>{pressRelease.title}</li>
))}
</ul>
{hasNextPage && (
<button type="button" onClick={fetchNextPage} >
もっと見る
</button>
)}
</div>
);
}
以上が初期の実装になります。この実装はNext.js移行をGoalとしていたため、無限スクロールの実装としては必要最低限なものになっており、無限スクロール特有の問題が残っていました。
ページ遷移した後にブラウザバックすると、2ページ目以降のデータが消える問題
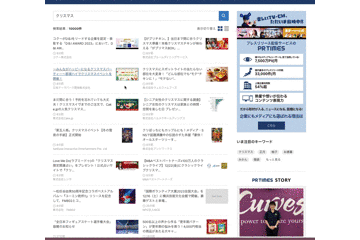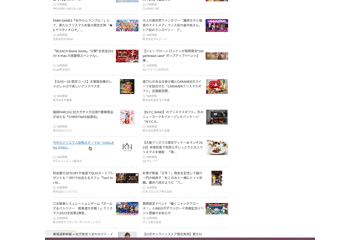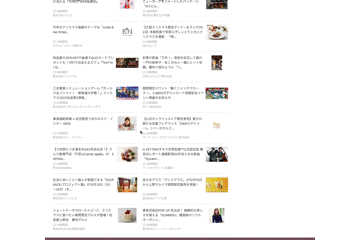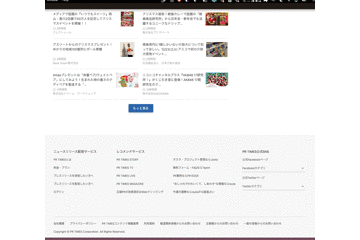
これは無限スクロールのUIではよく見られる問題ですが、UX的にはかなりクリティカルで実際にユーザーからはこの問題を回避するために毎回別タブで開くようにしているという声を聞いていました。
この問題の解決方法は色々と考えられます。
例えば、データをAjaxで取得した後、LocalStorageなどに保存しておき、ブラウザバック時に復元する方法や、「もっと見る」をクリックした際にクエリパラメータを書き換え、その値を参照してNext.jsからServer Side RenderingしたHTMLを返却する方法などです。しかし、それらの方法はアプリケーションコードを複雑にし、新たなバグが発生する可能性があったため、ブラウザ標準の機能を用いて解決することにしました。
BFCacheを利用したデータの復元
アプリケーションコードにほとんど手を加えることなくデータを復元するためにBFCacheを利用しました。
BFCacheの説明は以下の通りです。
BFCache(バックフォワードキャッシュ)は、ブラウザでページを遷移した時に、ページの完全なスナップショットとして保存されるメモリキャッシュを指します。通常遷移する場合はページが0から読み込み直されるに対し、BFCacheが有効の場合はページ全体のスナップショットから復元され、JavaScriptもそこから再開されます。元見ていた画面がそのままブラウザ上に復元される形で表示されるので、通常の遷移と比較して高速に表示されます。
https://techblog.yahoo.co.jp/entry/2023072430429932/
BFCacheを利用してデータ(ページ)を復元するために行ったことは以下の2つです。
- Cache-Controlヘッダーのno-storeを外す
- Ajaxでデータを取得した時にHistory APIのreplaceStateを実行する
Cache-Controlヘッダーのno-storeを外す
元々検索ページはキャッシュを一切しないようにしていたため、以下のようなCache-Controlヘッダーの設定となっていました。
Cache-Control: private, no-cache, no-store, max-age=0, must-revalidateこの設定は当時next.config.jsでグローバルに設定していたため、getServerSideProps内でCache-Controlヘッダーを書き換えてno-storeを外しました。
import {
dehydrate,
type DehydratedState,
QueryClient,
Hydrate
} from '@tanstack/react-query';
export const getServerSideProps = async ({req, res, query}) => {
const {search_word: searchWord} = query;
const queryClient = new QueryClient();
const searchResultResponse = await getSearchResult({searchWord, page: 1});
await queryClient.prefetchInfiniteQuery(
['searchResult', searchWord],
() => searchResultResponse.data,
);
if (searchResultResponse.data.total === 0) {
res.statusCode = 404;
}
// 追加したコード
+ res.setHeader(
+ 'Cache-Control',
+ 'private, no-cache, max-age=0, must-revalidate',
+ );
return {
props: {
searchWord,
dehydratedState: dehydrate(queryClient)
}
}
}
export default function Page({
searchWord,
dehydratedState
}: InferGetServerSidePropsType<typeof getServerSideProps>) {
return (
<Hydrate state={dehydratedState}>
<Component searchWord={searchWord} />
</Hydrate>
);
}Ajaxでデータを取得した時にHistory APIのreplaceStateを実行する
History APIのreplaceStateをAjax後に実行することで、データを取得した後のページが履歴として登録されます。これにより、ブラウザバックした時でもデータ取得後のページが表示されるようになります。
const useSearchResult = () => {
const searchWord = useSearchWord();
return useInfiniteQuery({
queryKey: ['searchResult', keyword],
async queryFn({pageParam}) {
const response = await getSearchResult({
searchWord,
page: typeof pageParam === 'number' ? pageParam : 1,
});
// 追加したコード
+ window.history.replaceState({}, '', window.location.toString());
return response.data;
},
getNextPageParam(data) {
if (data.currentPage < data.lastPage) {
return data.currentPage + 1;
}
return undefined;
},
retry: false,
});
}
const SearchResult = () => {
const {data, fetchNextPage, hasNextPage} = useSearchResult();
return (
<div>
<ul>
{data?.pages.map((pressRelease) => (
<li>{pressRelease.title}</li>
))}
</ul>
{hasNextPage && (
<button type="button" onClick={fetchNextPage} >
もっと見る
</button>
)}
</div>
);
}BFCacheを利用するようにした結果
上記の修正により、データの復元をすることができ、わざわざ別タブで開いたりする必要がなくなりました。

また、これまでPCでのデモ動画だけを載せていましたが、スマートフォンでも同様の処理を追加したため、スマートフォンでもデータを復元することができています。
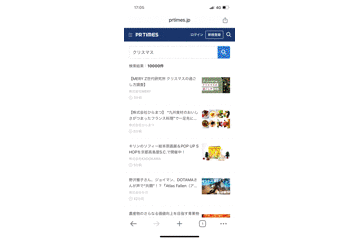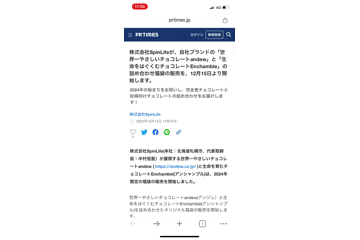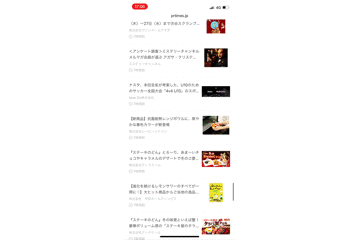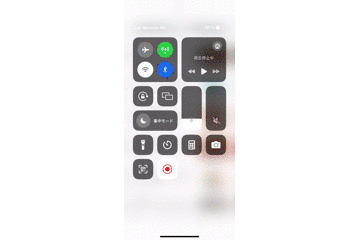
まとめ
今回は、BFCacheを使用して無限スクロールの一般的な問題を解決しました。アプリケーションコードのわずかな修正で実現でき、BFCacheの便利さを実感しました。しかし、無限スクロールには他にも問題があり、SEOに配慮した実装や、スクロールが進むとメモリが大量に使用される問題などはまだ解決できていません。今後さらなる改善を目指したいと考えています。
PR TIMESではフロントエンドはもちろんのこと様々な改善活動が行われているので、もしご興味ある方は、ぜひカジュアル面談でお話しできると嬉しいです。







