
皆さんこんにちは!PR TIMESの開発部のThaiです。今回はOpenSearchのMulti-Search APIを利用してWebクリッピングのクリップ調査のパフォーマンスを改善したことについて話します。

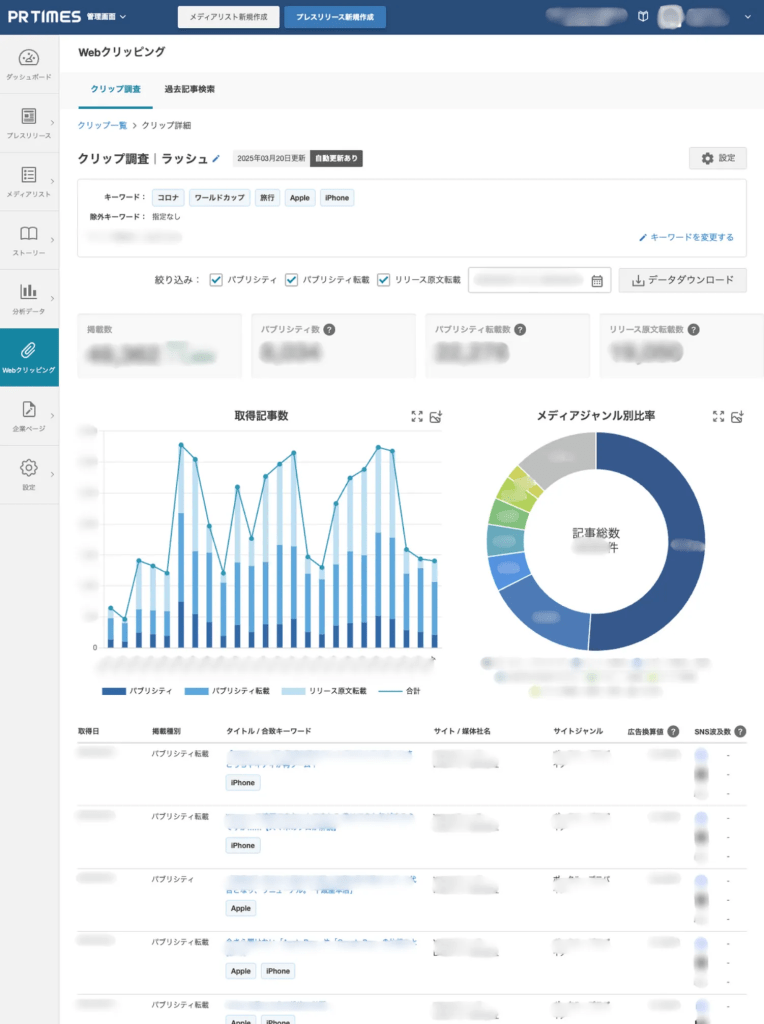
クリップ調査とは、設定したキーワードを含む記事を自動で収集する調査です。調査はクリップ作成後に開始し、期間は最長1年まで指定可能。調査結果はグラフや記事一覧で確認・ダウンロードできます。
クリップ調査の収集された結果は、以下のような形式で表示されます。
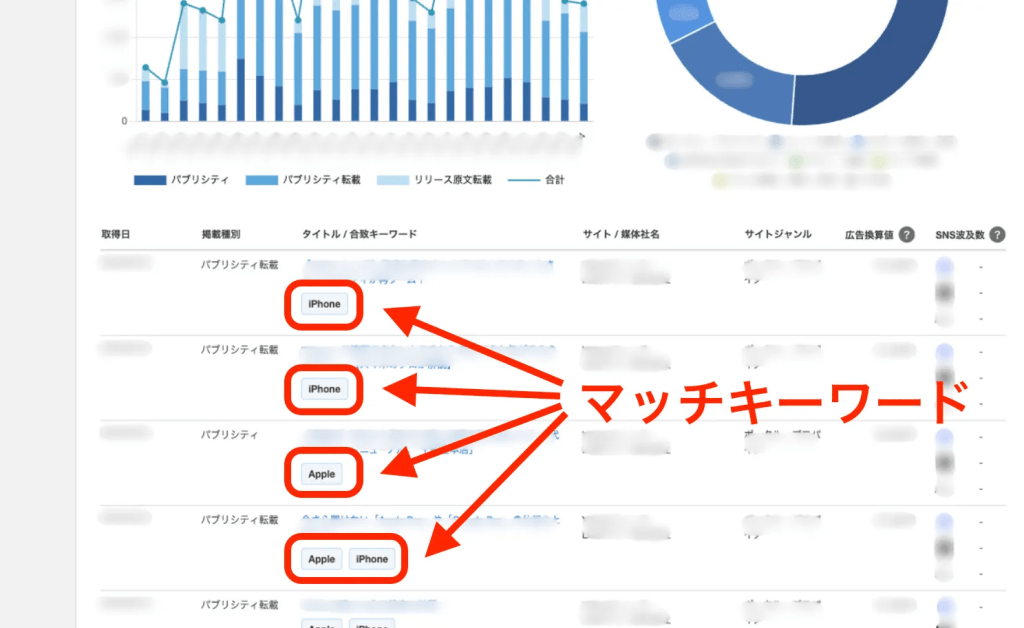
「マッチキーワード」とは?
クリップ調査の機能は、設定したキーワードに関係する記事を探します。さらに、どの記事がどのキーワードに該当するかも判別できます。Webクリッピングでは、記事の中にあるキーワードを「マッチキーワード」と呼びます。
たとえば、ユーザーが「Apple」「iPhone」「旅行」というキーワードでクリップをつくります。システムは「来月の旅行にそなえて、Appleで最新のiPhone16を買いました」という記事をみつけました。このとき、その記事のマッチキーワードは「Apple」「iPhone」「旅行」になります。
以前の方法の問題点
Webクリッピングでは全文検索エンジンとしてOpenSearchを活用していますが、課題がありました。OpenSearchの通常の検索クエリでは、複数のキーワードで検索した場合、返ってくるのはいずれかのキーワードに合致した記事のリストだけです。具体的にどのキーワードがどの記事に合致したかという情報は含まれていません。
この「マッチキーワード」を特定するという課題を解決するため、以前はexplain:trueというパラメータを利用していました。
explain:trueを有効にすると、OpenSearchは検索処理および結果の詳細を返しますが、その構造は非常に複雑です。
GET /index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"body": "Apple"
}
},
{
"match": {
"body": "iPhone"
}
},
{
"match": {
"body": "旅行"
}
}
]
}
},
"explain": true
}[“Apple”, “iPhone”, “旅行”]というキーワードで検索した場合、ヒットした記事1件に対するexplainの結果は、以下のような(簡略化した)形式になります。
"_explanation": {
"value": 1.834,
"description": "sum of:",
"details": [
{
// "Apple"がマッチしたことによるスコア計算の詳細
"value": 0.912,
"description": "weight(body:apple in 123) [PerFieldSimilarity], result of:",
"details": [
// ... さらにネストしたスコア計算の詳細 ...
]
},
{
// "iPhone"がマッチしたことによるスコア計算の詳細
"value": 0.922,
"description": "weight(body:iphone in 123) [PerFieldSimilarity], result of:",
"details": [
// ... さらにネストしたスコア計算の詳細 ...
]
}
...
]
}このレスポンスから「マッチキーワード」を特定するためには、アプリケーション側で以下の処理が必要でした。
- ヒットした記事ごとに、上のネスト構造を持つJSONを再帰的にパースする
- descriptionフィールド(例: “weight(body:apple in 123)…”)から、正規表現などを用いてマッチした単語(apple, iphoneなど)を抽出する
- 抽出した単語を、
Analyze APIの結果も考慮しながら元のキーワードリスト([“Apple”, “iPhone”])と照合し、どのキーワードが実際にマッチしたかを特定する。
この方法は、実装が非常に複雑であるだけでなく、ヒットした記事一件一件に対してこの重い処理を行うため、OpenSearchクラスターから「cancelled task with reason: heap usage exceeded」というエラーが出ました。
{
"error": {
"root_cause": [
{
"type": "rejected_execution_exception",
"reason": "cancelled task with reason: heap usage exceeded [2.2gb >= 10.3mb]"
},
{
"type": "rejected_execution_exception",
"reason": "cancelled task with reason: heap usage exceeded [2.3gb >= 10.3mb]"
},
{
"type": "rejected_execution_exception",
"reason": "cancelled task with reason: heap usage exceeded [2.1gb >= 10.3mb]"
}
],
...
}
}このエラーは、ヒープメモリの使用量が許容限界を超えたために発生します。調査の結果、主な原因は
explain:true の使用であることが判明しました。explainは「どのキーワードがマッチしたか」を調べるためには役立ちますが、その詳細な計算過程を出力するためにOpenSearchのCPUやメモリなどのリソースを大量に消費するのです。 エラーはステージング・開発環境でのみ発生していましたが、データ量が増加する本番環境でも同様の問題が発生する懸念があり、解決策を検討しました。
新しい抽出方法:Multi-Search APIによる改善
上記の問題を解決するために、OpenSearchのMulti-Search APIを導入しました。
このアプローチの最大のポイントは、上記の問題の原因だったexplain:trueを不要にできる点です。
複雑な単一の大きなクエリを投げる代わりに、キーワードごとに独立した単純な検索クエリに分割します。これらのクエリをMulti-Search APIで一度のHTTPリクエストにまとめて送信します。これにより、ネットワークの往復回数を増やすことなく、複数の検索を効率的に実行できます。
キーワードごとにヘッダー(インデックス指定)とクエリボディをペアにして並べるだけ、という非常に分かりやすい形式です。
GET /_msearch
// "Apple"のクエリ
{"index": "index"}
{"query": {"match": {"body": "Apple"}}}
// "iPhone"のクエリ
{"index": "index"}
{"query": {"match": {"body": "iPhone"}}}
// "旅行"のクエリ
{"index": "index"}
{"query": {"match": {"body": "旅行"}}}Multi-Search APIからのレスポンスは、リクエストしたクエリと同じ順序の結果が配列で返ってきます。
{
"responses": [
{ // "Apple"に対する検索結果
"hits": { "hits": [ /* ... */ ] }
},
{ // "iPhone"に対する検索結果
"hits": { "hits": [ /* ... */ ] }
},
{ // "旅行"に対する検索結果
"hits": { "hits": [ /* ... */ ] }
}
]
}これにより、どのレスポンスがどのキーワード(「Apple」など)に対応するかが明確になり、explain:trueを使わなくても、どの記事がどのキーワードにマッチしたかを簡単に特定できるようになります。
複数のキーワードがマッチする記事の扱い
では、一つの記事に複数のキーワードが含まれる場合はどう処理するのでしょうか。先ほどの「来月の旅行にそなえて、Appleで最新のiPhone16を買いました」という記事を例に考えてみましょう。
この場合、この記事は「Apple」「iPhone」「旅行」の3つのクエリ全ての検索結果に含まれることになります。
{
"responses": [
{ // "Apple"に対する検索結果
"hits": { "hits": [ /* ... 例の記事がここに含まれる ... */ ] }
},
{ // "iPhone"に対する検索結果
"hits": { "hits": [ /* ... 例の記事がここにも含まれる ... */ ] }
},
{ // "旅行"に対する検索結果
"hits": { "hits": [ /* ... ここにも含まれる ... */ ] }
}
]
}アプリケーション側では、レスポンス配列を順番に見ていき、記事IDごとにどのキーワードの検索結果に含まれていたかを記録します。
例えば、
- 最初のレスポンス(”Apple”の結果)に記事Aがあれば、「記事Aは”Apple”にマッチ」と記録します。
- 次のレスポンス(”iPhone”の結果)にも記事Aがあれば、「記事Aは”iPhone”にもマッチ」と追加で記録します。
- 同様に、3番目のレスポンス(”旅行”の結果)にも記事Aがあれば、「記事Aは”旅行”にもマッチ」と記録します。
この処理を全記事に対して行うことで、最終的に「記事AはApple、iPhone、旅行の3つのキーワードにマッチした」と簡単に特定できます。これは、複雑なexplainの結果をパースする以前の方法に比べて、はるかにシンプルで直感的な実装です。
検索速度とパフォーマンスの向上
Multi-Search APIに切り替えた後、良い結果が見られました。以前発生していた「cancelled task with reason: heap usage exceeded」というエラーは解消されました。また、OpenSearchのレスポンスタイムが約2〜3倍に速くなりました。

結論
OpenSearchでMulti-Search APIを利用することで、クリップデータ処理プロセスにポジティブな改善をもたらすことができました。これはOpenSearchの機能を活用し、パフォーマンスを最適化した一例です。もしあなたが検索パフォーマンスに関する同様の問題に直面しているなら、Multi-Search APIは有効な解決策となるかもしれません。







