
はじめに
皆さんこんにちは!PR TIMESの開発部のThaiです。今回はWebクリッピングからphpQueryを廃止したことについて話します。

Webクリッピングにおいて、クローラーは記事のURLやタイトルといった情報を収集する上で欠かせない役割を果たしています。この処理にはphpQueryを使っていました。長年にわたりPHPを用いたWebスクレイピングに携わってきた開発者にとって、phpQueryは馴染み深いライブラリと言えるでしょう。jQuery風の記法で操作ができるため、多くのプロジェクトで広く採用されてきました。私たちのチームも過去のプロジェクトでその利便性を大いに享受してきました。
しかしながら、phpQueryは長期間メンテナンスが停止しており、最新のPHPバージョンとの互換性やパフォーマンス面で課題が顕在化しています。サービスの品質向上と保守性確保を図るために、ライブラリの移行は避けて通れない重要な課題となりました。
本記事では、実施した調査の内容、ベンチマークテストの結果、さらには最終的に選定したライブラリの理由と具体的な移行計画について、技術的な視点から詳しくご紹介します。
phpQueryが抱える根本的な問題
phpQueryはいくつかの問題があります。
- 開発・保守の停止: 最終公式リリースから長期間経過(2009年頃、一部フォークは2017年頃まで更新があったが限定的)。バグ修正、パフォーマンス改善、新PHPバージョンへの対応が期待できない。
- PHP互換性問題: 最新のPHPバージョン (PHP 7.4+, PHP 8.x) で警告やエラーが発生する可能性。
- 低パフォーマンス: 大規模・複雑なHTMLドキュメント処理において、現代的なライブラリと比較して著しく遅い。DOM解析メカニズムが最適化されていない。
- バグとセキュリティリスク: 未保守ライブラリは未修正の脆弱性を含む可能性がある。
GitHub上の版(主にelectrolinux/phpqueryやそのフォーク)には、以下の注意書きがあります。
WARNING: abandonware and buggy: use at your own risk Note: I haven’t used this package since many years, and just recently looked at the code: this is scary, buggy and unfinished. Please don’t use it on any production server!
これは、ライブラリの憂慮すべき状態を裏付けています。
代替ライブラリの評価基準と候補
代替ライブラリは、以下の基準に基づいて評価しました。
- 機能性:基本的なDOM操作(テキスト・属性の取得など)を網羅しているか。
- パフォーマンス: 処理速度とメモリ使用量が優れているか。
- CSSセレクタのサポート: phpQuery のようにCSSセレクタで直感的に要素を検索できるか。
- メンテナンス状況: 活発に開発・保守されているか。
- 使いやすさ: APIが直感的で、ドキュメントが充実しているか。
これらの評価基準を踏まえ、対象となるPHPライブラリを検討しました。
評価対象として選定したライブラリ
- Simple HTML DOM (voku/simple_html_dom): PHPでHTMLを簡単にパース・操作できる軽量で使いやすいライブラリ。
- DiDOM (Imangazaliev/DiDOM): 高速かつシンプルなHTMLパーサー。
- Symfony DomCrawler (symfony/dom-crawler): Symfonyコンポーネントの一つで、非常に強力かつ高機能なDOM操作ライブラリ。
評価対象から除外したライブラリ
- Symfony Panther: JavaScriptで動的に描画されるページの解析には対応可能ですが、今回のような静的HTMLの処理には過剰であり、処理速度も遅いため、用途に適していません。よって評価対象から除外しました。
ベンチマークテスト
シナリオ1: 大規模HTMLファイルの解析と情報抽出
大規模HTMLファイル(約18000行、ファイルサイズは約1.7MB)を読み込み、指定されたセレクタで属性とテキストを繰り返し取得する処理の速度とメモリ使用量を測定しました。ライブラリごとに1000回実行して、以下の結果が得られました。
Benchmark Scrape Results:
Library Time (s) Memory (bytes) Content Accuracy URL Accuracy
---------------------------------------------------------------------------------------
phpQuery 1960.323722 46551904 Same Same
SimpleHtmlDom 321.486812 11377960 Same Same
DiDOM 284.750994 13716144 Same Same
SymfonyDom 277.364323 8804352 Same Sameこの結果から、Symfony DomCrawler はphpQueryと比較して約7倍高速であり、メモリ使用量も約1/5に抑えられていることがわかります。以下は使ったベンチマークテストのコードです。
/**
* HTML Scraper Performance Benchmark Test
*
* This class benchmarks the performance of different HTML scraping libraries
* (phpQuery, SimpleHtmlDom, DiDOM, SymfonyDom) by testing their execution time,
* memory usage, and result accuracy on a large HTML document.
*/
class SummaryTest
{
/** @var int Number of scraping iterations to perform for each library */
const SCRAPE_NUMBER = 1000;
/** @var int Starting article index for CSS selectors */
const START_ARTICLE_INDEX = 500;
/** @var int Number of href attribute selectors to test */
const HREF_SELECTOR_COUNT = 10;
/** @var int Number of text content selectors to test */
const TEXT_SELECTOR_COUNT = 10;
/** @var array Output file paths for each library's results */
private $outputFiles;
/** @var array Scraper class names mapped by library name */
private $scrapers;
/**
* Initialize scraper configurations and output file paths.
*/
public function __construct()
{
$this->outputFiles = array(
'phpQuery' => __DIR__ . '/scrape_result/phpQuery_output.txt',
'SimpleHtmlDom' => __DIR__ . '/scrape_result/SimpleHtmlDom_output.txt',
'DiDOM' => __DIR__ . '/scrape_result/DiDOM_output.txt',
'SymfonyDom' => __DIR__ . '/scrape_result/SymfonyDom_output.txt'
);
$this->scrapers = array(
'phpQuery' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\PHPQueryScraper',
'SimpleHtmlDom' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\SimpleHtmlDomScraper',
'DiDOM' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\DiDOMScraper',
'SymfonyDom' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\SymfonyDomScraper'
);
}
/**
* Execute the complete benchmark test suite.
*
* Runs performance benchmarks for all configured scraping libraries,
* comparing their execution time, memory usage, and result accuracy.
*
* @return void
*/
public function execute(): void
{
$htmlSource = file_get_contents(__DIR__ . '/data_test/largeSite.html');
$results = array();
$this->cleanupOutputFiles();
$hrefSelectors = $this->generateHrefSelectors();
$textSelectors = $this->generateTextSelectors();
foreach ($this->scrapers as $libraryName => $scraperClass) {
$results[$libraryName] = $this->runBenchmark($libraryName, $scraperClass, $htmlSource, $hrefSelectors, $textSelectors);
}
$this->displayResults($results);
}
/**
* Remove existing output files from previous benchmark runs.
*
* @return void
*/
private function cleanupOutputFiles(): void
{
foreach ($this->outputFiles as $file) {
if (file_exists($file)) {
unlink($file);
}
}
}
/**
* Generate CSS selectors for href attribute extraction.
*
* Creates selectors targeting link elements within article containers
* starting from START_ARTICLE_INDEX.
*
* @return array Array of CSS selectors for href attributes
*/
private function generateHrefSelectors(): array
{
$selectors = array();
for ($i = 0; $i < self::HREF_SELECTOR_COUNT; $i++) {
$articleIndex = self::START_ARTICLE_INDEX + $i;
$selectors[] = ".container-thumbnail-list article:nth-child({$articleIndex}) a.link-title-item";
}
return $selectors;
}
/**
* Generate CSS selectors for text content extraction.
*
* Creates selectors targeting article containers starting from
* START_ARTICLE_INDEX for text content scraping.
*
* @return array Array of CSS selectors for text content
*/
private function generateTextSelectors(): array
{
$selectors = array();
for ($i = 0; $i < self::TEXT_SELECTOR_COUNT; $i++) {
$articleIndex = self::START_ARTICLE_INDEX + $i;
$selectors[] = ".container-thumbnail-list article:nth-child({$articleIndex})";
}
return $selectors;
}
/**
* Run performance benchmark for a specific scraping library.
*
* Measures execution time and memory usage while performing
* multiple scraping operations using the specified library.
*
* @param string $libraryName Name of the scraping library
* @param string $scraperClass Fully qualified class name of the scraper
* @param string $htmlSource HTML content to scrape
* @param array $hrefSelectors CSS selectors for href attributes
* @param array $textSelectors CSS selectors for text content
* @return array Benchmark results containing time, memory, content, and url data
*/
private function runBenchmark(string $libraryName, string $scraperClass, string $htmlSource, array $hrefSelectors, array $textSelectors): array
{
$startTime = microtime(true);
$startMemory = memory_get_usage();
echo "[{$libraryName}] starting benchmark...\n";
$url = '';
$content = '';
for ($i = 0; $i < self::SCRAPE_NUMBER; $i++) {
$scraper = new $scraperClass($htmlSource);
foreach ($hrefSelectors as $selector) {
$url = $scraper->getAttribute($selector, 'href');
}
foreach ($textSelectors as $selector) {
$content .= $scraper->getTextContent($selector);
}
echo ".";
}
echo "\n[{$libraryName}] benchmark completed.\n";
$time = microtime(true) - $startTime;
$memory = memory_get_peak_usage() - $startMemory;
return array(
'time' => $time,
'memory' => $memory,
'content' => $content,
'url' => $url
);
}
/**
* Display benchmark results in a formatted table.
*
* Compares all library results against phpQuery as the baseline
* and displays execution time, memory usage, and accuracy metrics.
* Also saves normalized content to output files.
*
* @param array $results Benchmark results from all tested libraries
* @return void
*/
private function displayResults(array $results): void
{
echo "\nBenchmark Scrape Results:\n";
echo str_pad("Library", 20) . str_pad("Time (s)", 15) . str_pad("Memory (bytes)", 20) . str_pad("Content Accuracy", 20) . "URL Accuracy\n";
echo str_repeat("-", 87) . "\n";
$baseContent = $this->normalizeTextContent($results['phpQuery']['content']);
$baseUrl = $results['phpQuery']['url'];
foreach ($results as $library => $data) {
$dataContent = $this->normalizeTextContent($data['content']);
file_put_contents($this->outputFiles[$library], $dataContent);
$contentAccuracy = ($dataContent === $baseContent) ? 'Same' : 'Different';
$urlAccuracy = ($data['url'] === $baseUrl) ? 'Same' : 'Different';
printf(
"%-20s%-15f%-20d%-20s%s\n",
$library,
$data['time'],
$data['memory'],
$contentAccuracy,
$urlAccuracy
);
}
}
}
// Run the benchmark test
ini_set('memory_limit', '2048M');
(new SummaryTest())->execute();
シナリオ2: 複雑なCSSセレクタの互換性テスト
テストデータ
- 実際のシステムで使用されているCSSセレクタ設定(4000件以上) 各サイトごとにデータベース上で管理・登録されているCSSセレクタを用いています。これにより、複数のサイトに対応した柔軟な解析が可能となっています。
本番環境で実際に使用されている4000件以上のCSSセレクタを各ライブラリで実行し、エラーの発生件数を比較しました。
Total sites to test: 4604
...
========================================
CSS SELECTOR TEST RESULTS
========================================
Simple HTML DOM : 222 errors
Symfony Dom Crawler : 222 errors
DiDOM : 642 errors
========================================テストコード
/**
* CSS Selector compatibility tester for multiple HTML parsing libraries
*/
class ProductionCssSelectorTest
{
private const DATA_FILE = __DIR__ . '/data_test/crawler_site_20250609.json';
private const HTML_FILE = __DIR__ . '/data_test/largeSite.html';
private const ERROR_DIR = __DIR__ . '/errors_css_selector';
private const SCRAPERS = [
'Simple HTML DOM' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\SimpleHtmlDomScraper',
'Symfony Dom Crawler' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\SymfonyDomScraper',
'DiDOM' => '\PRTIMES\Clipping\Platform\Feature\Crawler\Lib\DiDOMScraper'
];
/**
* Run CSS selector tests for all libraries
*/
public function execute(): void
{
$data = json_decode(file_get_contents(self::DATA_FILE), true);
$htmlContent = file_get_contents(self::HTML_FILE);
echo "Starting CSS Selector Test...\n";
echo "Total sites to test: " . count($data) . "\n";
$results = [];
foreach (self::SCRAPERS as $name => $class) {
$errorFile = self::ERROR_DIR . '/' . strtolower(str_replace(' ', '_', $name)) . '_errors.txt';
$this->clearErrorFile($errorFile);
$scraper = new $class($htmlContent);
$results[$name] = $this->testLibrary($scraper, $data, $errorFile, $name);
}
$this->displayResults($results);
}
/**
* Test a scraper library against all sites
*/
private function testLibrary($scraper, array $data, string $errorFile, string $name): int
{
echo "\nTesting {$name}...\n";
$errorCount = 0;
foreach ($data as $site) {
$listSettings = json_decode($site['list_setting'], true);
$detailSettings = json_decode($site['detail_setting'], true);
$siteErrors = 0;
// Test all selectors
$selectors = [
['block', $listSettings['block'] ?? null, $site['full_resource_flag']],
['list_ignore', $listSettings['list_ignore'] ?? null, $site['full_resource_flag']],
['next_page', $listSettings['next_page'] ?? null, $site['full_resource_flag']],
['title', $detailSettings['title'] ?? null, $site['detail_resource_flag']],
['body', $detailSettings['body'] ?? null, $site['detail_resource_flag']],
['detail_ignore', $detailSettings['detail_ignore'] ?? null, $site['detail_resource_flag']],
['all_view', $detailSettings['all_view'] ?? null, $site['detail_resource_flag']],
['writer_tag', $detailSettings['writer_tag'] ?? null, $site['detail_resource_flag']],
['pageing', $detailSettings['pageing'] ?? null, null] // Always test if present
];
foreach ($selectors as [$name, $selector, $flag]) {
if ($this->shouldTest($selector, $flag) && !$this->testSelector($scraper, $selector, $site['id'], $errorFile)) {
$siteErrors++;
}
}
$errorCount += $siteErrors;
echo $siteErrors > 0 ? 'E' : '.';
}
echo "\n";
return $errorCount;
}
/**
* Test a single CSS selector
*/
private function testSelector($scraper, string $selector, int $siteId, string $errorFile): bool
{
try {
$scraper->hasElement($selector);
return true;
} catch (\Exception $e) {
file_put_contents($errorFile, "Site {$siteId}: {$selector} - {$e->getMessage()}\n", FILE_APPEND);
return false;
}
}
/**
* Check if selector should be tested
*/
private function shouldTest(?string $selector, $flag): bool
{
return !empty($selector) && ($flag === null || (int)$flag === 0);
}
/**
* Clear error file
*/
private function clearErrorFile(string $file): void
{
if (file_exists($file)) unlink($file);
}
/**
* Display test results
*/
private function displayResults(array $results): void
{
echo "\n" . str_repeat("=", 40) . "\n";
echo "CSS SELECTOR TEST RESULTS\n";
echo str_repeat("=", 40) . "\n";
foreach ($results as $library => $errors) {
printf("%-20s: %d errors\n", $library, $errors);
}
echo str_repeat("=", 40) . "\n";
}
}
// Suppress deprecated warnings for cleaner output
error_reporting(E_ALL & ~E_DEPRECATED);
// Set memory limit for processing large datasets
ini_set('memory_limit', '2048M');
// Run the benchmark test
(new ProductionCssSelectorTest())->execute();Symfony Dom Crawler と Simple HTML DOM は、内部で同じ CSS セレクタ変換ライブラリ(symfony/css-selector)を使用しているため、結果は同数でした。一方、DiDOM はサポートしていないセレクタ構文が比較的多く、エラー件数が最も多くなりました。発生したエラーの多くは、無効なCSSセレクターや各ライブラリがサポートしていない特定のCSSセレクタです。以下は各ライブラリーのテスト結果(エラー数)です。
Simple HTML DOMでのエラー数

Symfony Dom Crawlerでのエラー数

DiDOMでのエラー数

ライブラリ比較のまとめと最終提案
分析とテスト結果に基づき、 Symfony DOM Crawler を選びました。
- 卓越したパフォーマンス: ベンチマークが示す通り、処理速度が圧倒的に速く、メモリ効率も最も優れています。これにより、システム全体のパフォーマンスが向上し、安定稼働に貢献します。
- 優れたCSSセレクタ互換性: 既存の複雑なセレクタに対する互換性が高く、移行時の修正コストを最小限に抑えられます。
- 高い信頼性と活発なメンテナンス: Symfonyという巨大なエコシステムの一部であり、専門チームによって継続的に保守されています。これにより、セキュリティリスクや将来のPHPバージョンへの非互換性といった問題を根本的に解決できます。
移行計画
リスクを最小限に抑えつつ、スムーズな移行を実現するために、以下のステップで計画を進めました。
- ラッパークラスの実装 Symfony DOM Crawler を内包する新しいラッパークラス (SymfonyDomManipulator) を作成し、既存の phpQuery ラッパーと同じメソッドを実装することで、ライブラリの差し替えを容易にします。
- テストカバレッジの確保と互換性の検証 移行の安全性を担保するため、まず既存のクローラーに対するユニットテストを作成・拡充します。このテストを用いて、新旧ライブラリの挙動の違いを明確にします。
- 未サポートCSSセレクタの特定と修正 phpQueryと違ってSymfony DOM Crawler は不正なセレクタに対して例外を投げるため、移行前にシステム内に存在するすべての未サポートセレクタを特定し、修正する必要があります。
- 段階的な置き換えと検証 ステージング環境で徹底的な動作検証とパフォーマンステストを行い、問題がないことを確認してから本番環境へリリースします。
次のセクションでは、この計画をどのように実行に移したか、その具体的なプロセスと技術的アプローチを詳述します。
ラッパークラスの実装
移行計画の第一歩である「ラッパークラスの実装」について、具体的なコード例を見ていきましょう。ここでの目的は、Symfony Dom Crawler の強力な機能を、より使いやすく、再利用可能なメソッドとしてカプセル化(隠蔽)することです。 以下に、記事のテキストコンテンツやURLを抽出するための基本的なメソッドの実装例を示します。

DomManipulatorInterface.php
<?php
declare(strict_types=1);
namespace PRTIMES\Clipping\Platform\Feature\Crawler\Lib;
use DOMElement;
interface DomManipulatorInterface
{
/**
* Find an element matching the given CSS selector.
*
* @param string $selector a CSS selector
* @return DOMElement|null the first element found, or null if no element is found
*/
public function querySelector(string $selector): ?DOMElement;
/**
* Find all elements matching the given CSS selector.
*
* @param string $selector a CSS selector
* @return DOMElement[] an array of elements found
*/
public function querySelectorAll(string $selector): array;
/**
* Remove all elements from DOM matching the given CSS selector.
*
* @param string $selector a CSS selector
* @return void
*/
public function remove(string $selector): void;
/**
* Get text of an element
*
* @param string $selector a CSS selector
* @return string|null
*/
public function getTextContent(string $selector): ?string;
/**
* Get an attribute of an element
*
* @param string $selector a CSS selector
* @param string $attribute the attribute name
* @return string|null the attribute value
*/
public function getAttribute(string $selector, string $attribute): ?string;
}
PHPQueryScrapper.php
<?php
declare(strict_types=1);
namespace PRTIMES\Clipping\Platform\Feature\Crawler\Lib;
require_once __DIR__ . '/../../../../../../class/phpQuery/phpQuery.php';
use DOMElement;
use Exception;
use phpQuery;
use phpQueryObject;
class PHPQueryScraper implements DomManipulatorInterface
{
/**
* @var phpQueryObject
*/
protected $dom;
/**
* PHPQueryScraper constructor.
*
* @param string $html_source The HTML source to be parsed.
* @throws Exception If the HTML source is invalid or cannot be parsed.
*/
public function __construct(string $html_source)
{
// Using `newDocumentHTML` instead of `newDocument` to ensure that the HTML is parsed correctly.
$this->dom = phpQuery::newDocumentHTML($html_source);
}
public function querySelector(string $selector): ?DOMElement
{
$queryResults = $this->dom->find($selector);
if ($queryResults instanceof phpQueryObject && $queryResults->length > 0) {
$element = $queryResults->get(0);
if ($element instanceof DOMElement) {
// Ensure that the element is an instance of DOMElement before adding it to the array
return $element;
}
}
return null;
}
public function querySelectorAll(string $selector): array
{
$queryResults = $this->dom->find($selector);
$elements = [];
if ($queryResults instanceof phpQueryObject && $queryResults->length > 0) {
for ($i = 0; $i < $queryResults->length; $i++) {
$element = $queryResults->get($i);
if ($element instanceof DOMElement) {
// Ensure that the element is an instance of DOMElement before adding it to the array
$elements[] = $element;
}
}
}
return $elements;
}
public function remove(string $selector): void
{
/** @var phpQueryObject $elements */
$elements = $this->dom->find($selector);
if ($elements->length > 0) {
$elements->remove();
}
}
public function getTextContent(string $selector): ?string
{
$element = $this->querySelector($selector);
if ($element === null) {
return null;
}
return $element->textContent;
}
public function getAttribute(string $selector, string $attribute): ?string
{
$element = $this->querySelector($selector);
if (is_null($element)) {
return null;
}
return $element->getAttribute($attribute);
}
}SymfonyDomManipulator.php
<?php
declare(strict_types=1);
namespace PRTIMES\Clipping\Platform\Feature\Crawler\Lib;
use DOMElement;
use Symfony\Component\DomCrawler\Crawler;
class SymfonyDomManipulator implements DomManipulatorInterface
{
/** @var Crawler */
protected $crawler;
public function __construct(string $htmlSource)
{
$this->crawler = new Crawler($htmlSource);
}
public function querySelector(string $selector): ?DOMElement
{
$node = $this->crawler->filter($selector)->first();
if ($node->count() > 0) {
$element = $node->getNode(0);
if ($element instanceof DOMElement) {
return $element;
}
}
return null;
}
public function querySelectorAll(string $selector): array
{
$nodes = $this->crawler->filter($selector);
$elements = [];
foreach ($nodes as $node) {
if ($node instanceof DOMElement) {
$elements[] = $node;
}
}
return $elements;
}
public function remove(string $selector): void
{
$this->crawler->filter($selector)->each(function (Crawler $node) {
$domNode = $node->getNode(0);
if ($domNode !== null && $domNode->parentNode !== null) {
$domNode->parentNode->removeChild($domNode);
}
});
}
public function getTextContent(string $selector): ?string
{
$node = $this->crawler->filter($selector)->first();
if ($node->count() > 0) {
return $node->text();
}
return null;
}
public function getAttribute(string $selector, string $attribute): ?string
{
$node = $this->crawler->filter($selector)->first();
if ($node->count() > 0) {
$element = $node->getNode(0);
if ($element instanceof DOMElement) {
return $element->getAttribute($attribute);
}
}
return null;
}
}
テストカバレッジの確保と互換性の検証
移行前、既存のPHPクローラーにはユニットテストがほとんど存在しないという課題がありました。そこで私たちは、まず phpQuery の現行の挙動を保証するためのテストを作成することから始めました。
そこで、上記に書いた「シナリオ2: 複雑なCSSセレクタの互換性テスト」のコードを再利用して、ユニットテストを作成しました。追加したテストにより、実際に本番環境で使っているセレクタの中に問題のあるセレクタがあったことがわかりました。
未サポートCSSセレクタの特定と修正
Symfony Dom Crawler は、不正なCSSセレクタを渡されると例外をスローし、クローラーの動作を停止させます。これは信頼性の観点では望ましい挙動ですが、移行を完了するためには、本番環境に存在するすべての不正なセレクタを事前に解消する必要がありました。
以下のアプローチでこの課題に取り組みました。
新規の不正セレクタ登録を防止する(管理画面の機能改修)
管理画面に「CSSセレクタチェック機能」を追加しました。これにより、管理者がセレクタを保存する際に構文を検証し、不正なセレクタがデータベースに登録されるのを未然に防ぎます。
SymfonyのDomCrawlerはHTMLの操作に便利なライブラリですが、内部ではXPathのみを扱います。CSSセレクタを使う場合は、まずSymfonyのCssSelectorConverterライブラリでCSSセレクタをXPathに変換する必要があります。

そのため、この仕組みを利用してCSSセレクタのバリデーション機能を作りました。具体的には、CssSelectorConverterのtoXPathメソッドにCSSセレクタを渡し、変換時に例外が投げられれば「不正なセレクタ」と判定します。例外が発生しなければ有効なセレクタとして扱い、保存可能です。
/**
* Check if the given CSS selector is supported.
*
* @param string $selector The CSS selector to check.
* @return array{
* status: bool,
* message: string
* } An associative array with 'status' indicating support and 'message' providing details.
*/
public static function checkSupport(string $selector): array
{
$converter = new CssSelectorConverter();
try {
// Attempt to convert the CSS selector to XPath to validate its syntax
$converter->toXPath($selector);
return [
'status' => true,
'message' => 'The CSS selector is supported.'
];
} catch (Exception $e) {
// If the selector is not supported, it will throw an exception
return [
'status' => false,
'message' => $e->getMessage()
];
}
}この方法は、Symfony公式ライブラリのパーサーをそのまま利用するため正確かつシンプルで、自前で複雑なバリデーションを作る必要がありません。
チーム連携による修正作業
テストで抽出した不正CSSセレクタのリストを基にチケットを作成し、メディアメンテナンスチームと連携して修正作業を進めました。修正後のセレクタは、管理画面のチェック機能を用いて検証しました。
この体系的な取り組みの結果、システム内に存在するすべてのCSSセレクタが Symfony Dom Crawler と互換性を持つ状態になりました
【修正前の状況】

【修正後の状況】
リリース後の監視と最終的な廃止
phpQuery を利用するコードを無効化した後、万全を期すために1週間の監視期間を設けました。New Relicの専用ダッシュボードを用いてクローラーの稼働状況を注意深くモニタリングし、パフォーマンスやエラーレートに異常がないことを確認しました。
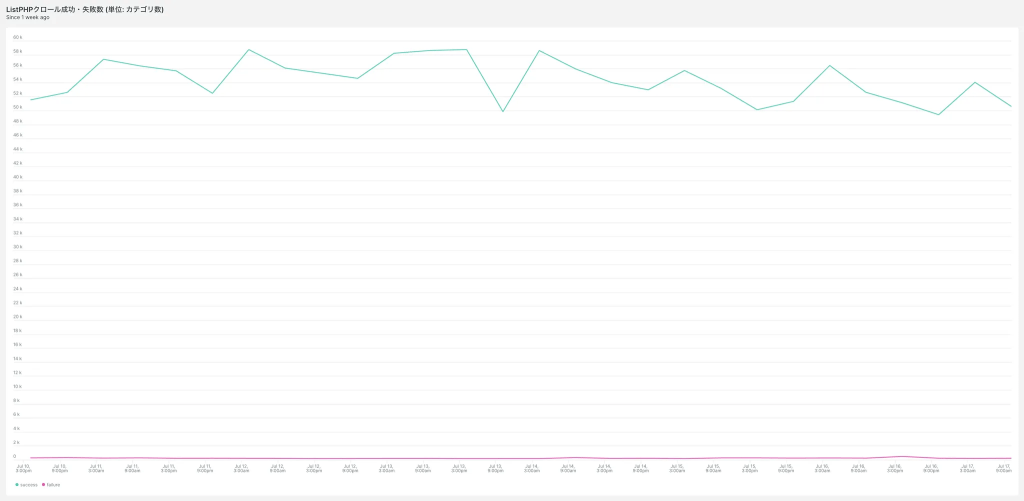
この監視期間中に特に問題が発生しなかったため、プロジェクトから phpQuery のコードと依存関係を完全に削除し、移行を完了しました。
まとめ
本記事の要点は、phpQueryという技術的負債を解消し、Symfony DOM Crawlerへ移行した経験の共有です。 このプロジェクトで最も学びが多かったのは、ライブラリの置き換えは「コードを書き換えるだけではない」という点でした。既存の不正データを洗い出して修正し、安全にリリースするためのテスト戦略を立てる。そうした地道な準備こそが、移行を成功に導く鍵だと実感しました。 古い技術を刷新する取り組みは大変ですが、やり遂げた後の達成感は格別です。この経験が、誰かの次の一歩を後押しできれば嬉しく思います。







