
こんにちは、PR TIMESでインターンをしている笹山雷雅です。
この記事では、バックエンドエンジニアを中心にNew Relicに転送されるエラーを減らす活動を行い、転送されるエラーをバックエンドチームで協力し、約7割減少させた経験について紹介します。
背景
PR TIMESでは、運営しているサービスのログやエラーをNew Relicに転送して監視を行っています。
New Relic内には、サービスで発生するエラーや例外が転送される「Errors(エラーインボックス)」がありますが、これまでのPR TIMESのバックエンドからは大量のエラーが転送されていました。
その結果、常にアラートが鳴っている状態で、重要なエラーがWARNINGやException、ログレベルが不適切に設定されたエラーログに埋もれてしまい、発見しづらくなっていました。さらに、障害対応時にも、障害になるログの他に不要なログが多く、対応の妨げになっていました。
改良が必要なことはバックエンドを担当するエンジニアの間で既に認識されていましたが、他の優先度の高いタスクがあったため、手が空いているエンジニアがそれぞれ得意な領域で少しずつ対応している状況でした。
そこで、自分が新たなチャレンジをしたいと手を挙げ、エラーを減らす活動の手伝いをすることになりました。
多すぎるログを分類する
エラーを減らすにあたり、最も難しいハードルは、バラバラな形式のログが大量に存在しているため、ログを個別に見ただけでは問題の特定が困難であることです。さらに、発生頻度もNew RelicのErrorsからは確認しづらい状況になっていました。
そこで、まずログの分類から取り組むことにしました。
NRQLを使ってデータを取り出す
NewRelicには、データを問い合わせるための独自のクエリ言語であるNRQLが用意されています。
一般的なSQLと書き方は大きく異ならず、まずErrorsに分類されるログとその発生頻度を取得しました。以下は実行したNRQLの一例です。
SELECT
count(*)
FROM TransactionError
WHERE appName = 'PRTIMES'
FACET error.message
SINCE 1 week ago
LIMIT MAX
NRQLは、FACET(GROUP BY句に相当)に指定したカラムを自動的に出力に含めるため、一般的なSQLとは異なる利点があります。実行結果はCSV形式で出力できるため、詳細な集計作業はスプレッドシートを利用して行うことも可能です。

改善前のエラーの問題点と、詳細な分類
改善前のエラーログは、発生したエラーの内容をそのままerror.messageに出力していたため、類似のエラーでも数値が異なり、FACETでの集約が難しくなっていました。
先述のNRQLで得たCSVファイルをスプレッドシートで分類作業を行いました。

今後、誰でも継続的に改善ができる点を重視し、複雑で高機能なマクロやスクリプトを使うのではなく、スプレッドシートに標準で備わっているSUMIFやCOUNTIF関数を用いて出現回数を計算しました。
B列の「合計Invocation」は「Transaction Errors」を指定したSUMIF関数、C列の検索で出てきた数はCOUNTIF関数で計算しました。
「CSV」というシート名にNRQLで出力した結果を添付し、以下のような計算をセルに記述しました。
- 合計Invocation
- SUMIFは集計する数値が必要なので、第3引数にTransaction ErrosになっているD列を指定します。
=SUMIF(CSV!B:B, "*" & A2 & "*", CSV!D:D)- 検索で出てきた数
=COUNTIF(CSV!B:B, "*" & A2 & "*")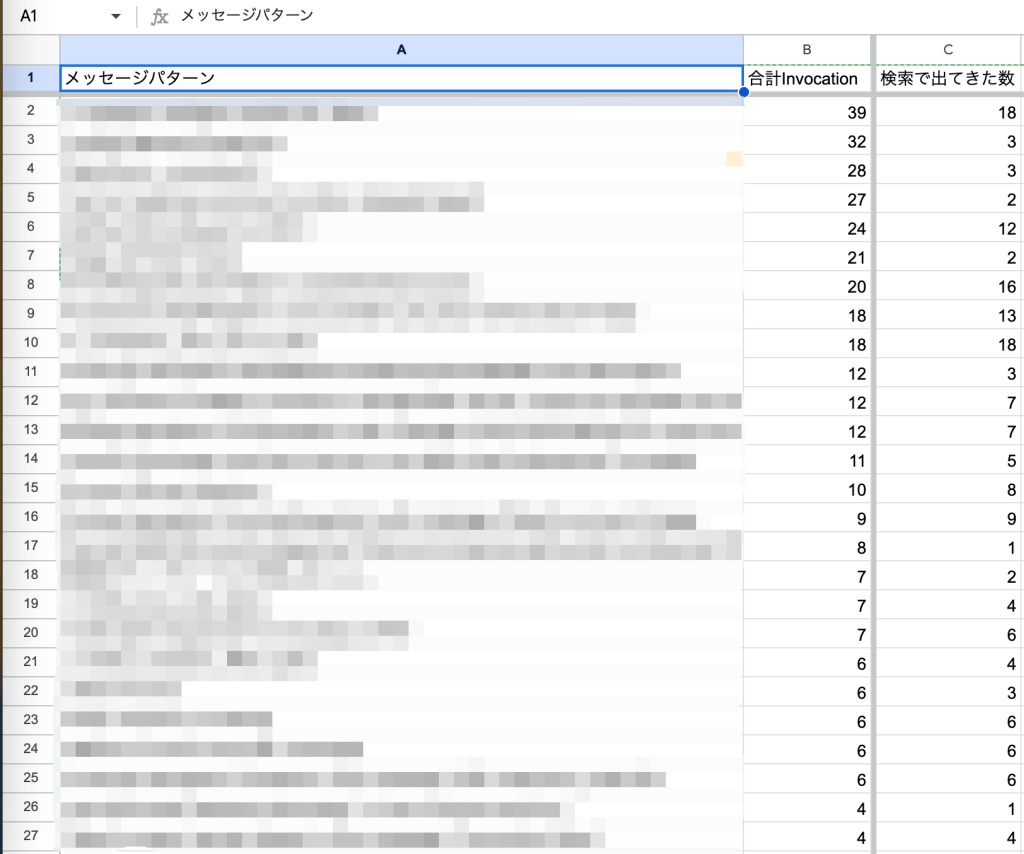
分類した結果、「合計Invocation」と「検索で出てきた数」の差から、同様のエラーがNew Relicで同じエラーとして認識されていないことが多いことがわかりました。また、cURLのタイムアウトなど、コードに起因しないエラーもかなり多く存在することが明らかになりました。
定例での呼びかけ
大まかな分類ができたものの、一人でこれらを解決するのは非常に困難でした。そのため、先輩エンジニアと相談の上、バックエンドを主に担当しているエンジニアが週に1回、定例を開催することにしました。
定例では、事前に分類・整理したスプレッドシートを使い、自分にできそうなエラーを自分でアサインしたり、ランダムに数個ずつ振り分ける形で割り当てを決定しました。PR TIMESでは月に1回、リファクタリングに専念できる「リファクタリングデー」が設けられているため、そのタイミングで大半の改善作業を行いました。
PR TIMESで行なっているリファクタリングデーは、以下の記事で詳しく説明されています。

具体的な実装
改善前後で挙動が変わらないように、ログの追加調査を行い、適切なログレベルに変更するとともに、出力形式の改善を行いました。
NewRelicでグルーピングできないログは、以下のようなログ実装になっていました。
$logger->error(
sprintf(
'%s. Hoge returned an error; message: %s; trace: %s',
__FILE__,
$e->getMessage(),
$e->getTraceAsString()
)
);$e->getMessage() や$e->getTraceAsString() は発生するケースによって毎回異なるため、error.message がバラバラになり、グルーピングが困難になっていました。
messageをグルーピングしやすいようにシンプルなものにし、追加で必要な情報は、loggerのcontextに入れる形式に変更しました。これにより、NewRelic上でmessageでのグルーピングが容易になり、ログの詳細はLogs in contextを活用し閲覧できるようになりました。
$logger->notice('Hoge Error', [
'exception' => $e,
'filename' => __FILE__,
// その他にログに必要な変数など
]);Logs in Contextについては、以下の記事で詳しく説明されています。

改善前後のエラー数の比較
改善前後のエラー数を比較した結果は以下の表の通りです。
| 集計期間 | Invocation数 | グループ数 |
|---|---|---|
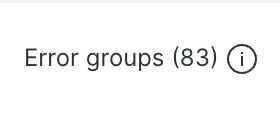
| 改善前(11/12-11/17) | 513 | 83 |
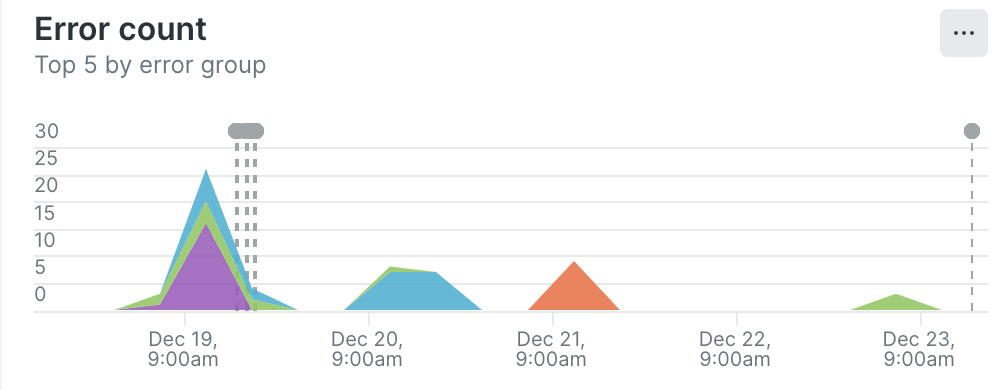
| 改善後(12/19-12/24) | 162 | 61 |
改善前
Error count

Error groups
改善後
Error count
Error groups

今回約一ヶ月の改善活動を通じて、エラーのInvocation数を約70%減らすことができました!
今後の改善点
エラーをスプレッドシートでSUMIF関数やCOUNTIF関数を用いて集計した際、検索するための文字列は手作業で400行以上目視確認したため、今後の活動では何らかの自動化がなされると、より効率的に集計ができると感じています。
また、NRQLでデータを集める際にログレベルを出力していなかったため、優先度がわかりづらい結果につながりました。今後はログレベルも判断基準にするようNRQLをアップデートしていきたいと考えています。
まとめ
New RelicのErrorsを占有していた不要なログを分類・集計し、オブザーバビリティの向上に向けた取り組みを紹介しました。
オブザーバビリティの向上は直接プロダクトの価値を提供しないものですが、日常業務の利便性や障害時の迅速な対応を可能にする重要なインフラです。この重要な改善に挑戦できたことは、私にとって貴重な経験となりました。
この記事が何かお役に立てれば幸いです。







